Waico (Wellbeing AI Companion), pronounced weiko, is a Mobile App that leverages Gemma 3n and other on-device AI models to provide personalized wellbeing support through multiple specialized AI agents. The system combines conversational AI with Gemma 3n, computer vision for pose landmark detection with Mediapipe, health data integration, and tailored optimizations for on-device performance to create a comprehensive wellbeing platform.
The app operates entirely offline using locally deployed AI models, ensuring user privacy while providing real-time, intelligent interactions across counseling, fitness coaching, and meditation guidance. With more modules to come.
Since 2020, during the coronavirus pandemic, the world has seen a significant increase in mental health issues, with many people struggling with anxiety, depression, and loneliness. The numbers keep rising, and the demand for mental health support with them.
Many surveys, including the Post-Pandemic Remote Work Health Impact 2025 show the need for mental health support, with 75% of respondents reporting a mental health status of Anxiety, Burnout, Depression, or PTSD.
Preliminary downloads for January 2025 were up slightly year-over-year (YoY) to reach their highest total since January 2022. Meanwhile, IAP revenue in January 2025 soared 10% YoY to reach a new all-time high at $385 million.
Source: Sensor Tower | 2025 State of Mobile: Health & Fitness
Although there are many apps trying to address this issue, most of them require you to book an appointment, then pay for the session regardless of your condition. And during the session, if you don't have a stable internet connection, you won't be able to make the most of your session.
Waico aims to solve this problem by providing a free and open, fully offline, on-device AI companion that can assist you with your mental health needs anytime, anywhere. It combines the power of advanced AI models with a user-friendly interface to create a personalized wellbeing experience.
Many AI-powered mental health apps will probably emerge. However, conversations with an AI are not protected by the same legal confidentiality laws that apply to licensed human counselors or therapists. Waico mitigates this risk by running all AI models locally on the user's device, ensuring that no data ever leaves the device. Putting the user in full control of their data and privacy. In a sense, true AI counseling privacy is only possible with on-device AI.

The AiAgent component serves as the foundation for all AI interactions in Waico. It implements a tool-calling system that allows AI models to interact with the real world through a predefined set of tools.

At initialization, each agent's system prompt is dynamically enhanced with contextual information. This includes the available tool definitions, relevant data from the user's information memory, and examples of how to use the tools. This enhancement ensures that the agent is aware of its capabilities and the user's context from the very beginning of the interaction.
To optimize for on-device performance, Waico employs a custom code-based function calling mechanism instead of a standard JSON-based approach. JSON generation by LLMs can be token-intensive, leading to higher memory consumption and slower response times, which are critical constraints on mobile devices.
Our approach defines a clear, code-like syntax for tool calls that the LLM generates directly. For example, instead of generating a JSON object, the model outputs
```tool_call
search_memory(query="The issue that happened at the user's aniversary party when they were 12")
```
This method significantly reduces the number of tokens required for both the tool definitions in the system prompt and the generated tool calls, nearly halving the token count compared to JSON. This optimization is crucial for achieving fast, responsive AI interactions on mobile hardware. A parser is then used to interpret these string-based commands and execute the corresponding functions with the provided arguments.
We built a multilingual dataset of 2275 samples to finetune Gemma 3n on this function calling format:
- English ~47%
- French ~24%
- Spanish ~15%
- German ~14%
The reason for this is not to teach Gemma the format. With just a prompt, you can get it to output in this format. The goal is to teach it when to use the tools, especially the memory tool, as it was failing to do this correctly based on our test. Also, when to ask for additional information and when to infer input based on the chat history and user information in the system prompt. Unfortunately, we couldn't fine-tune it, as there is no way to use a fine-tuned Gemma 3N with mediapipe at the moment. We had to tweak the System again and again and provide usage examples.
The agent implements a multi-iteration tool execution system:

This pipeline allows agents to:
- Execute multiple tools in parallel: For example, fetching user data and searching memory can happen simultaneously, improving efficiency.
- Chain tool calls: An agent can use the output of one tool as the input for another in a subsequent iteration, enabling complex, multi-step workflows.
- Handle tool failures gracefully: If a tool call fails, the agent is informed of the error and can attempt to correct it by changing the input or notifying the user.
- Maintain conversational context: The agent retains the history of the conversation and tool usage, allowing for coherent and context-aware interactions.
Waico implements a dual memory system that combines shared user context with agent-specific episodic memories:

The conversation processor employs multiple AI-driven extraction techniques:
- Memory Extraction: Identifies significant moments, key decisions, and important emotional expressions from the conversation that are worth remembering long-term.
- Summarization: Creates concise overviews of conversations, useful for quick recaps.
- Clinical Observations: Generates professional-grade notes that can be shared with healthcare providers, capturing relevant details in a structured format.
- User Information Updates: Detects changes in user information (e.g., new goals, updated contacts) and updates them.
All agents share access to a centralized user information store that includes:
- Personal Details: Name, preferences, goals
- Professional Contacts: Therapist, coach, doctor contact information
- Context Information: Current situation, ongoing challenges
- Preferences: Communication style
This information is automatically injected into every agent's system prompt, enabling personalized interactions without requiring users to re-establish context. This ensures that every agent, whether it's the Counselor or the Workout Coach, is aware of the user's overall profile and can tailor their responses accordingly.
The RAG (Retrieval-Augmented Generation) memory system provides long-term episodic memory, allowing the agent to recall past events from the user's life. This is crucial for maintaining continuity and providing personalized, context-aware support over time.
These extracted memories from the conversations are converted into vector embeddings and stored in a vector database for efficient retrieval. When a user evokes a moment (e.g, Do you remember that time when...) or asks a question that requires long-term memory, the agent uses the search_memory tool that queries the vector database to find the most relevant memories, which are then used to generate a contextual response.
The counselor agent provides emotional support and mental health guidance. It is designed to be a compassionate and helpful companion, offering a safe space for users to express themselves.
Capabilities:
- Evidence-based therapeutic approaches: Utilizes principles from Cognitive Behavioral Therapy (CBT), Acceptance and Commitment Therapy (ACT), and mindfulness to guide conversations.
- Active listening and emotional validation: Acknowledges and validates the user's feelings, fostering a sense of being heard and understood.
- Progress tracking: Integrates with health data like sleep and mood (coming soon) to monitor progress and provide insights into the user's wellbeing journey.
- Professional communication: Can generate reports and facilitate communication with the user's healthcare providers.
Available Tools:
SearchMemoryTool: Accesses important events and milestones extracted from conversations to maintain long-term context.DisplayUserProgressTool: Visualizes historical health and wellness data.ReportTool: Generates professional reports for healthcare providers, summarizing progress and key observations.PhoneCallTool: Initiates direct communication with health services or the user's support network, such as a therapist or trusted contact.CreateCalendarSingleEventTool: Schedules appointments, workouts, reminders for medication, or other important events. There are additional tools already implemented but not being used at the moment to reduce the complexity until there is a way to use finetuned Gemma 3n models on mobile with mediapipe.
This agent generates personalized, guided meditation sessions. Instead of relying on pre-recorded audio, it creates unique scripts tailored to the user's current needs and mood.
The agent first generates a script that includes pauses of varying lengths (e.g., ...breathe in deeply... [pause 5s] ...and now breathe out...). This script is then processed by a Text-to-Speech (TTS) model, which converts the text portions into audio chunks. These chunks are saved locally. During playback, the app plays the user's chosen background music and then sequences the audio chunks, inserting silent intervals corresponding to the pauses in the script. This creates a seamless and immersive meditation experience that feels dynamic, responsive, and personalized.
The workout coach specializes in providing real-time form correction and motivation during exercise sessions. It acts as a virtual personal trainer, helping users exercise safely and effectively.
Key Features:
- Real-time pose analysis: Uses the device's camera to analyze the user's form in real-time.
- Exercise-specific corrections: Provides targeted feedback based on the specific exercise being performed.
- Adaptive motivational coaching: Adjusts its motivational cues based on the user's performance and signs of fatigue.
- Safety-first approach: Prioritizes user safety by identifying and correcting potentially harmful movements.
Feedback System:

The coach analyzes real-time data, including:
- Joint positions and angles: To ensure proper alignment and range of motion.
- Movement velocity and consistency: To assess the quality and control of each repetition.
- Fatigue indicators: Such as slowing rep speed or deteriorating form.
When building such systems with a multimodal LLM, the first thing that you think about is to input the image stream to the LLM, which then outputs feedback and Reps counting. But to accurately do this, your LLM and environment should be able to process around 10 images per second, which is not realistic on mobile devices as of 2025. That's why we used Mediapipe pose landmark detection to extract the user's body landmarks in real-time, and use holistic algorithms for each supported exercise to validate that the user is fully visible in the camera and is doing the right exercise, determine up/down position, and compute form metrics based on joint angles and distances.
The same token-efficient approach used for function calling is also applied to workout plan generation. Instead of generating a large JSON object, the model generates a structured text format that is then parsed to create the workout plan. This significantly reduces generation time and makes the feature more responsive.
Waico leverages MediaPipe for real-time, on-device pose landmark detection. This powerful framework provides detailed information about the user's body position without needing to send any data to the cloud.

The process begins with the camera stream, which is fed into the MediaPipe Pose Landmark Detection model. The model identifies 33 key body landmarks, providing a detailed, 3D representation of the user's pose. This landmark data is then passed to the Exercise Classifier.
The system uses the detected pose landmarks, specifically the angles of various body joints, to classify the user's position (up/down) and analyze their form.
The system supports multiple exercise types with specialized analysis:
Reps-based Exercises:
- Push-ups: Standard, knee, wall, incline, decline, diamond, wide
- Squats: Standard, split, sumo
- Core exercises: Crunch, reverse crunch, double crunch, superman
Duration-based Exercises:
- Planks: Standard, side planks
- Wall sits
- Cardio movements: Jumping jacks, high knees, mountain climbers
These exercises are chosen to ensure the whole body is covered with different exercise categories.
Waico runs entirely on-device using a stack of optimized AI models.

The core of the language understanding is Gemma 3n, a powerful yet efficient large language model. The model is accelerated using the device's GPU with the help of mediapipe's LLM inference to ensure real-time performance. For memory retrieval, we use the Qwen3 Embedding 0.6B model, which generates high-quality embeddings. For other models:
- Text To Speech: We use Kokoro and Piper
- Speech To Text: nemo-fast-conformer-transducer-en-de-es-fr (We will talk about why we are using a Speech To Text model later)
- Voice Activity Detection: Silero v4
The voice chat pipeline orchestrates seamless, real-time voice-based interactions, making it feel like a natural conversation.

The pipeline starts with Voice Activity Detection (VAD), which listens for the user to start and stop speaking. This allows for a hands-free experience. Once a speech segment is detected, it is sent to the Speech-to-Text (STT) model, which transcribes the audio into text. This text is then passed to the AI agent, which processes the input and generates a response. The response is streamed to the Text-to-Speech (TTS) model, which converts it into audio chunks that are played back in real-time. This streaming approach ensures that the user hears the agent's response as it's being generated, reducing perceived latency.
Currently, the MediaPipe versions of Gemma 3n don't support audio input (no framework for mobile inference supports it as of now), which is why we use a separate Speech To Text model. Once MediaPipe adds audio modality support for Gemma 3n, the pipeline will be simplified:

This future architecture will allow for an even more seamless and efficient interaction, as the agent will be able to directly process audio inputs and get more insights, like the user's emotions.
In every choice made when building Waico, the user experience was a key factor. It’s no secret that the responsiveness of an app plays a crucial role in user experience — no one likes clicking a button and watching a loading spinner for 30 seconds. With on-device AI, especially when it comes to LLMs, this is a great challenge. Despite the impressive on-device performance of Gemma 3n on mediapipe, which uses several optimizations like KV cache, generating a full workout plan on mobile will still take several seconds to minutes, depending on the device.
Let's first talk about how we made it possible to talk to Waico in real-time. When chatting (text format) with Gemma 3n there is no latency issue even on some low-end devices because mediapipe supports streaming, you can read the model output as it's being generated. However, in voice mode, the Text to Speech models don't support synthesizing speech from a stream (at least not those that can run on mobile); you have to input the whole text. Waiting for the LLM to finish generating the response and then synthesizing the speech would be extremely slow:
- We have to wait for the whole answer to be generated
- Synthesizing the entire response at once will be very slow
To address these issues, we parse the text stream from Gemma 3n and detect all the punctuations that cause a pause when reading. Then split the text at those punctuations and feed these chunks that can be read individually while keeping the naturalness of the speech to the Text To Speech model, which can synthesize it quickly since it's a small input.
When it comes to the workout plan generation, besides avoiding the JSON format, there wasn't much we could do. The generation will still take time, so we focused on providing visual feedback so the user knows what's going on, instead of just showing a circular progress bar. We show the user the workout sessions with their details as they are being generated, with an option to see the text stream or the UI:
| Generating First Session | Generating Second Session | Text Stream |
|---|---|---|
 |
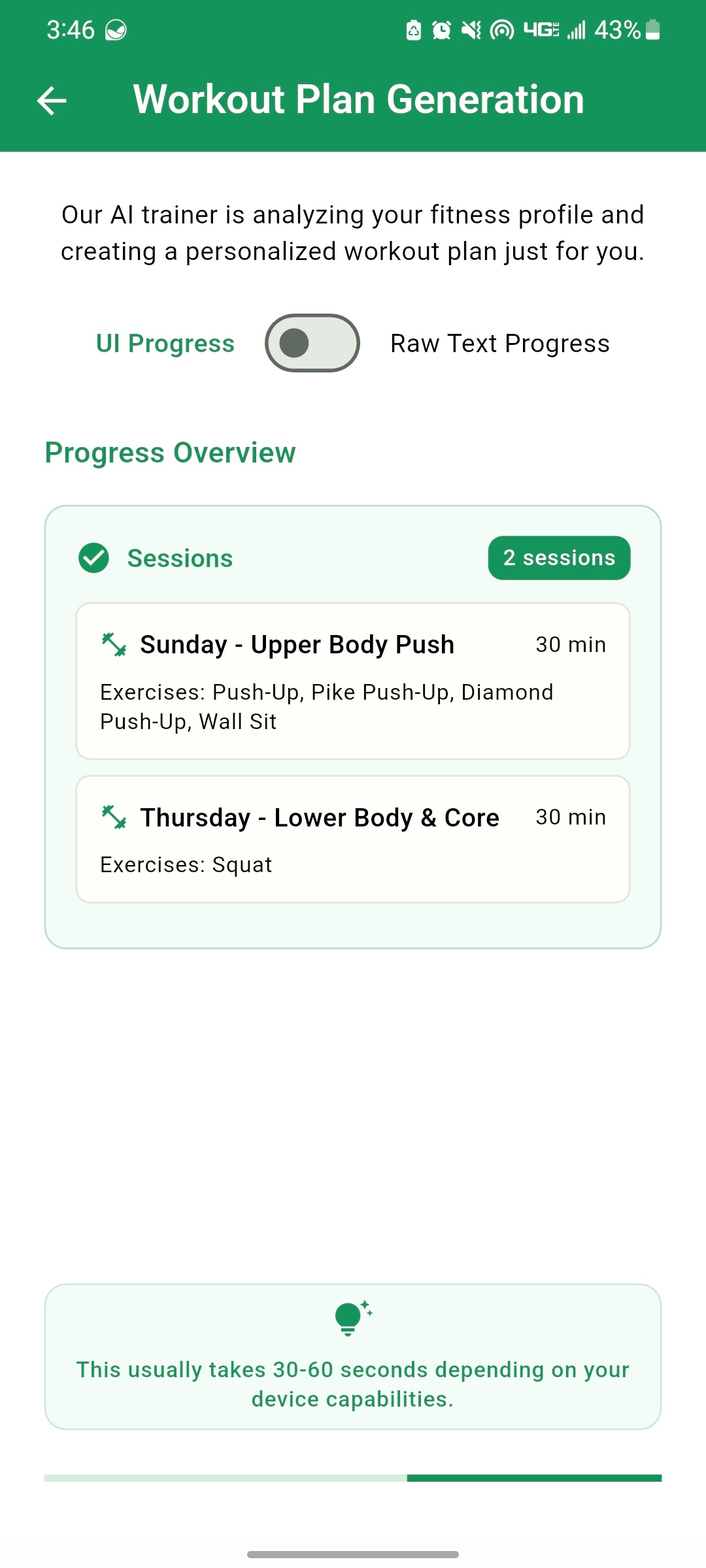 |
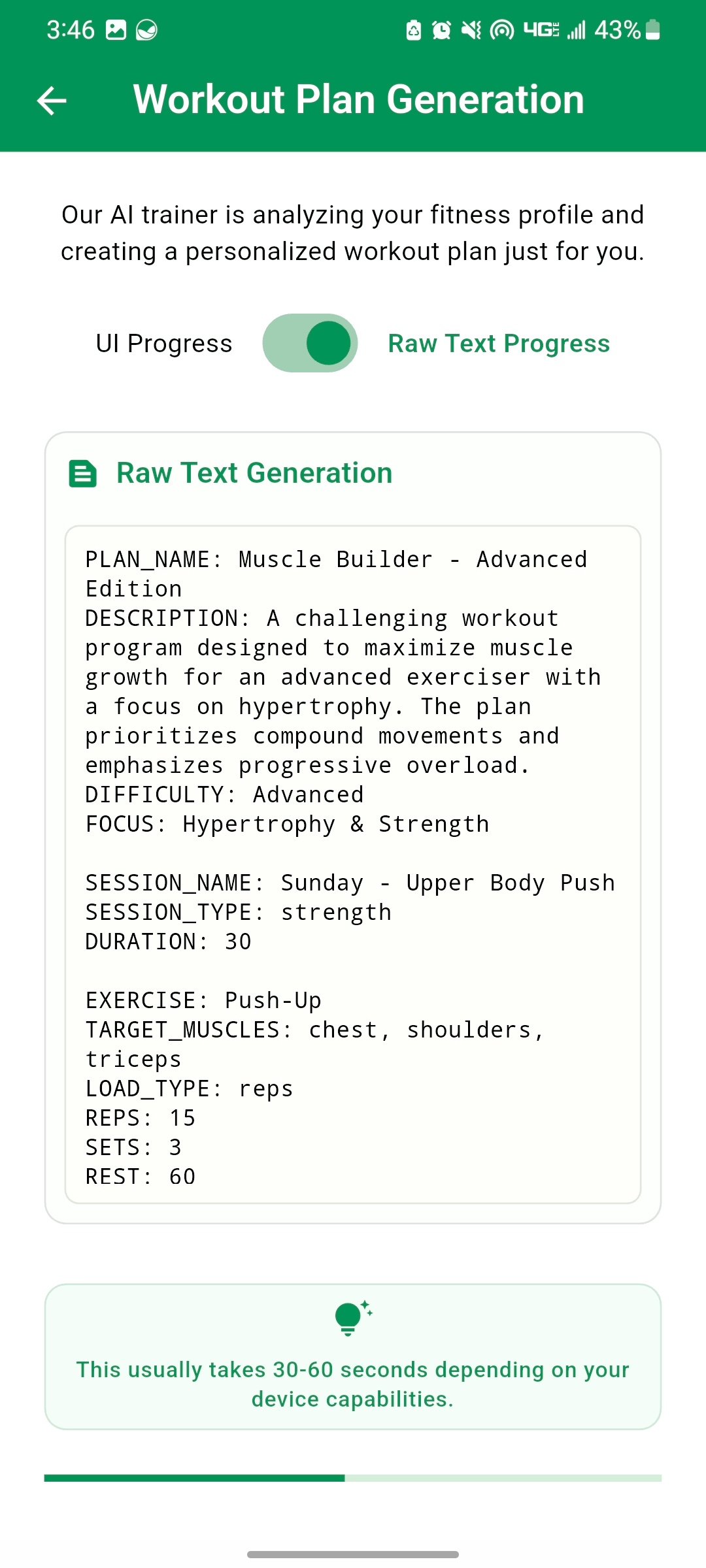 |
The counselor supports 2 communication methods, speech and text, allowing people with disabilities related to hearing or vision to interact with it.
Not everyone has a high-end device, so to make sure more people can have access to Waico, we provide 2 flavors for the models that require the most compute power, allowing the user to choose the model based on the performance of their device. The available options are:
- Gemma 3n E2B (Lite) and E4B (Advanced) for the chat model
- Kokoro (Advanced) and Piper(Lite) for the Text-to-Speech model.
Waico also supports 3 Languages for now (although in text mode, you can speak to it in any language supported by Gemma 3N):
- English
- French
- Spanish
| Select Model Based on Device Perf | Select App Language |
|---|---|
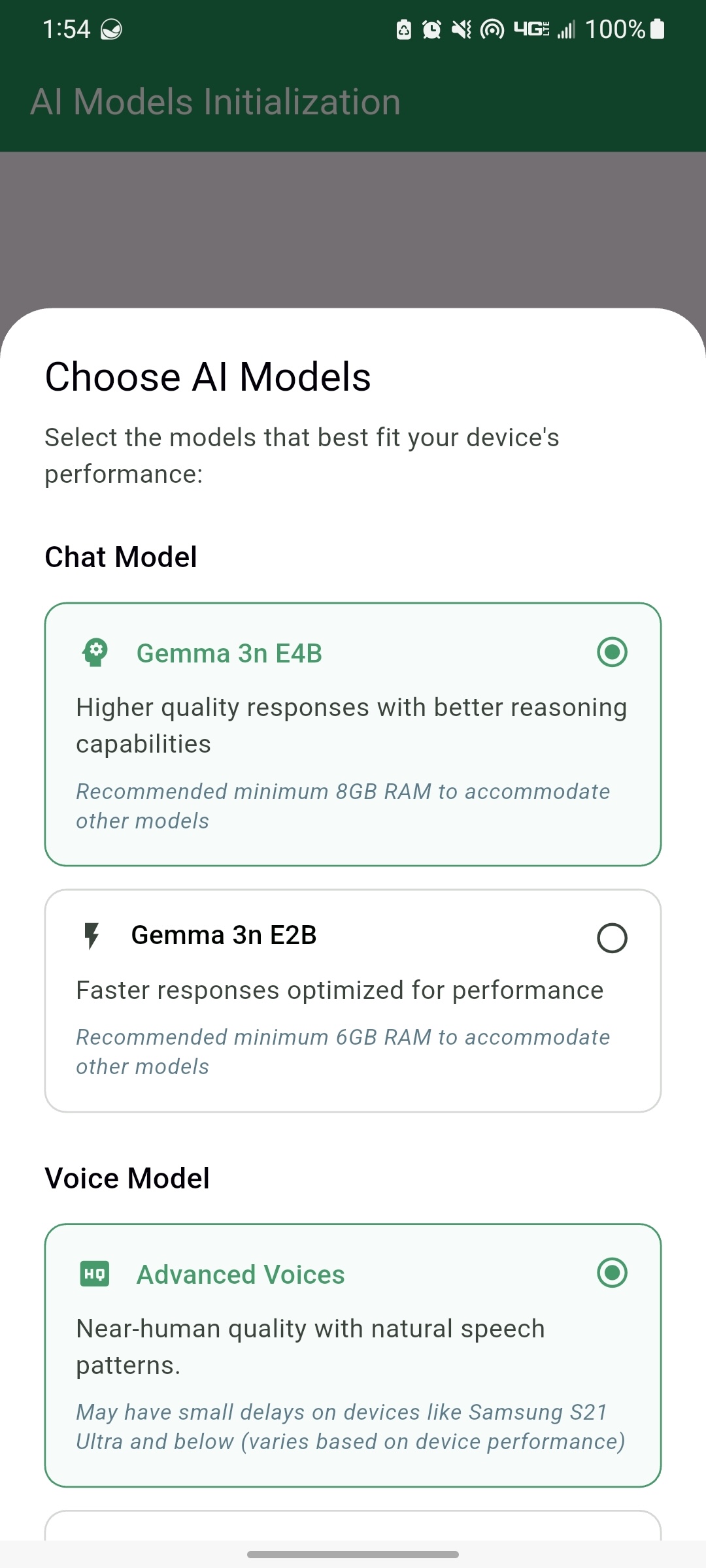 |
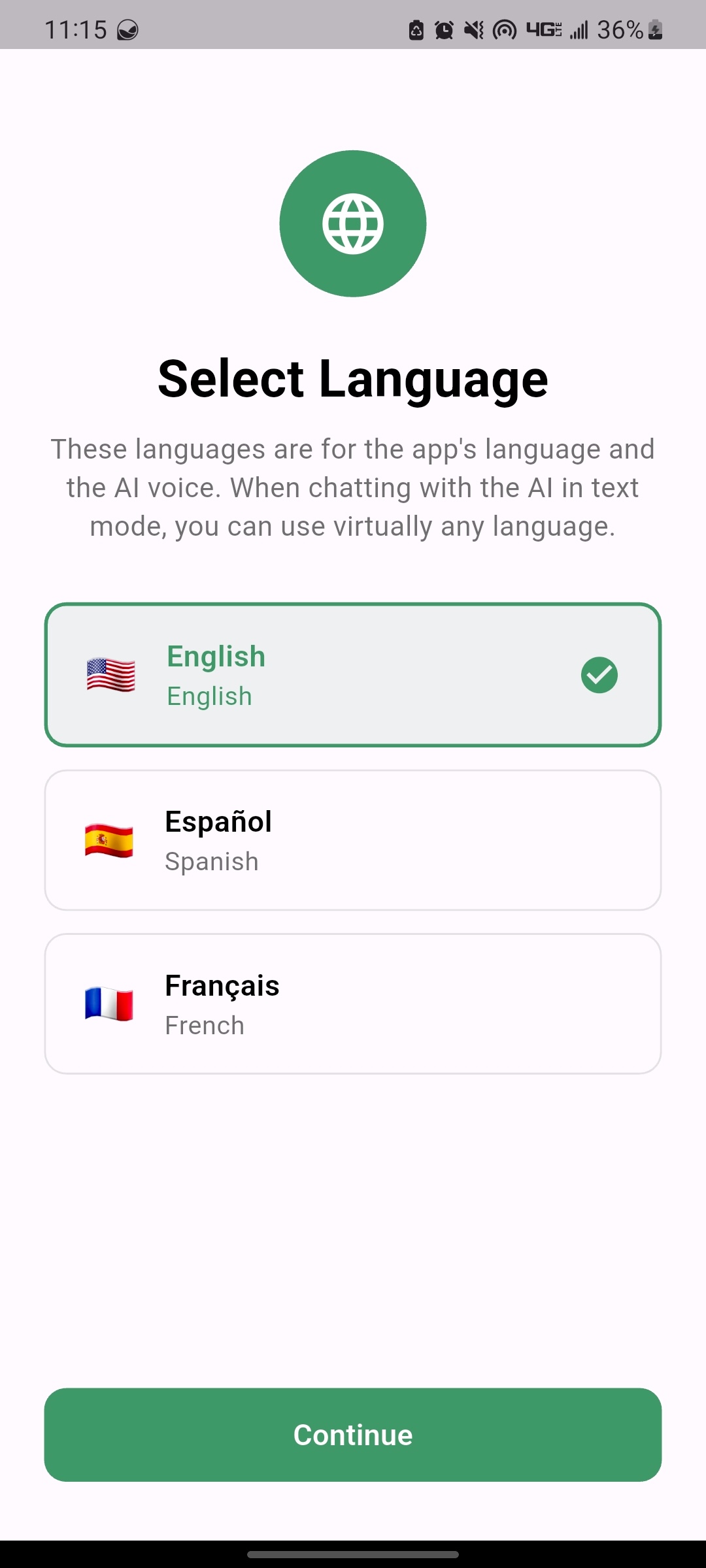 |
We need less memory than recommended to load the models, but as you speak to the AI, the memory usage will increase.
Building agents on mobile isn't the same as building them in Python. The Python world has many libraries that make it super easy to build Agents and RAG pipelines. However, in Flutter (and mobile in general), there are only API clients to interact with the agents hosted in the cloud. There are no tools to build agents on-device. Mediapipe is building APIs for both function calling and RAG that are still in preview and only available in Android Native. So we had to build everything ourselves. As for vector databases, we had only one option available on Android and IOS, ObjectBox DB. We believe that the demand for such tools on mobile will keep increasing as more people adopt on-device AI.
At the time of writing this, only Mediapipe LLM Inference and Llama.cpp support Gemma 3n inference on mobile devices. But Llama.cpp only supports text inputs, and the Mediapipe models are still in preview and don't support audio input. We, and many people, have been tracking this on the different Google AI Edge repositories, but no timeline is given for the support of audio input, and the possibility of using fine-tuned models either through LoRA or exporting your own model. Many times, when we test Gemma 3n E2B with a prompt in Google AI Studio, it works well. But when we try with the Mediapipe model, we don't get very good results, which is expected when the model is 4-bit quantized, but it sometimes outputs unexpected responses or keeps repeating the same sequence.
It also seems like Gemma 3n models' training was too strict about privacy and safety guidelines. You can tell them that a tool is completely safe and harmless, and that the tool is built to help it better assist the user. But when the user asks to use the tool, more than 5 out of 10, they respond that they can't perform the action due to safety guidelines. A problem that could be fixed with fine-tuning.
All this made it quite challenging to build Waico in the given timeline. Especially the Counselor Agent, which needs to have a specific tone, have access to many tools it needs to know how and when to use, and support voice communication.
Waico represents a sophisticated convergence of on-device AI, and wellbeing domain expertise. The architecture is designed to provide personalized, intelligent, and private assistance by leveraging the power of modern AI systems running locally on the user's device.
The dual memory system, combining shared user context with RAG-based episodic memory, enables continuity and deep personalization across different interaction modes. The specialized agent architecture allows for domain-specific expertise in counseling, meditation, and fitness, all while maintaining a coherent and unified user experience.
The real-time pose detection and feedback system showcases the potential for AI-powered fitness coaching, while the voice-first interaction model, combined with intelligent conversation processing and token-efficient strategies, creates an intuitive, accessible, and responsive user experience that sets a new standard for wellbeing applications.