The OpenWings Project is a scientific research project having the goal of inferring a time-calibrated phylogeny for all of the world's ~10,000 bird species (class Aves). To generate this phylogeny, we have collected DNA sequence data from genomic libraries that have been enriched for a class of genomic markers known as ultra-conserved elements or UCEs. The enrichment process effectively increases the concentration of UCE loci relative to the rest of the genome, and we sequence the enriched product. More details on the UCE enrichment process can be found in this publication.
The set of 4,434 loci targeted for this project (5Kv2A and 5Kv2B) are a slightly modified subset of UCE loci commonly used in other studies of birds (e.g. Oliveros et al. 2018). More information on the target enrichment baits used for this study can be found in the OpenWings Bait repository.
We are providing the "raw" reads that we have generated from genomic libraries enriched for UCE loci. It is important to note that these data HAVE NOT been rigorously quality controlled. The taxonomy of the individuals sequenced also HAS NOT been verified or standardized. Those processes are ongoing.
What this means is that we think these data represent the species indicated and the loci targeted, but we have not performed analyses to verify that this is the case. Verification is an ongoing process. This also means some species labels could be incorrect.
The data for each species are 150 base pair (bp), paired-end (PE), Illumina sequencing reads (i.e., PE150). Data are formatted as fastq.gz files, and each species in the dataset has both a R1 and a R2 file (representing each of the paired reads). File names look like the following - e.g., the two read files for the species Rhea pennata:
B-10338.LSUMZ.TISS-3:D4.Rhea-pennata.R1.fq.gz
B-10338.LSUMZ.TISS-3:D4.Rhea-pennata.R2.fq.gz
The file naming convention is:
[Museum_Accession].[Museum_Code].[DNA_Plate]:[DNA_Row][DNA_Column].[Genus]-[species].[Read]
| [Museum_Accession] | This is the accession number of the particular tissue used for DNA extraction, target enrichment, and DNA sequencing. This may correspond to a tissue sample in a collection OR to a specimen/skin within a given collection. |
| [Museum_Code] | This is the INSDC code for the institution providing the tissue/toepad used for DNA extraction. Generally speaking, the combination of the [Museum_Code] and [Museum_Accession] should be referenced every time that data from this specimen are used. |
| [DNA_Plate] | This is the DNA extraction plate in which a particular specimen was placed. Values of TISS-, LOAN-, INTL- correspond to tissues, and values of TP- correspond to toepads. |
| [DNA_Row] | This is the row location of the sample in the DNA extraction plate. |
| [DNA_Column] | This is the column location of the sample in the DNA extraction plate. |
| [Genus]-[species] | This is the likely species of the individual from which a tissue/toepad was collected. The taxonomy of these individuals has not necessarily been standardized because these values were given by the institution providing the tissue. |
| [Read] | This is a value of R1 for read 1 and R2 for read 2. |
Before downloading any data, install the AWS Command Line Interface for your operating system. Advanced users may also use other options (e.g. boto, etc.), but these are not described here. The top-level bucket in which all files are stored is s3://openwings-project/.
The data are temporarily stored (see NCBI SRA Identifiers) on Amazon Web Services in their S3 Cloud Object Storage system. As such, you can easily use tools like the AWS Command Line Interface to view different buckets in which the data are stored (corresponding to sequencing runs), as well as all of the files within a given bucket. For instance, after installing the AWS CLI, here is an example session:
# be sure that the AWS CLI is installed and configured correctly.
# Show the contents of the openwings project:
aws s3 ls s3://openwings-project/data/
PRE 2024-openwings-FB01Q001/
# now that we have a list of buckets/sequencing runs
# (right now just showing 2024-openwings-FB01Q001),
# let's look inside of each sequencing run to see what
# files are included in that run. In general, each sequencing
# run includes roughtly 450 GB of sequencing data from 600ish libraries:
aws s3 ls s3://openwings-project/data/2024-openwings-FB01Q001
# which returns (truncated):
2025-06-02 12:57:15 313848551 B-10338.LSUMZ.TISS-3:D4.Rhea-pennata.R1.fq.gz
2025-06-02 12:57:15 327712812 B-10338.LSUMZ.TISS-3:D4.Rhea-pennata.R2.fq.gz
2025-06-02 12:57:15 264624310 B-10387.LSUMZ.TISS-6:B6.Incaspiza-pulchra.R1.fq.gz
2025-06-02 12:57:15 274103714 B-10387.LSUMZ.TISS-6:B6.Incaspiza-pulchra.R2.fq.gz
2025-06-02 12:57:15 516552614 B-10617.LSUMZ.TISS-10:B1.Brachygalba-albogularis.R1.fq.gz
2025-06-02 12:57:42 530902095 B-10617.LSUMZ.TISS-10:B1.Brachygalba-albogularis.R2.fq.gz
2025-06-02 12:57:42 322739926 B-10703.LSUMZ.TISS-9:A4.Liosceles-thoracicus.R1.fq.gz
2025-06-02 12:57:42 329907755 B-10703.LSUMZ.TISS-9:A4.Liosceles-thoracicus.R2.fq.gz
...
# let's say you want to download the data for the B-66112.LSUMZ.TISS-3:A1.
# Crypturellus-transfasciatus.R1.fq.gz library.
#
# To download individual files to the local directory in which you are working, you can:
aws s3 cp s3://openwings-project/data/2024-openwings-FB01Q001/B-66112.LSUMZ.TISS-3:A1.Crypturellus-transfasciatus.R1.fq.gz ./
# followed by
aws s3 cp s3://openwings-project/data/2024-openwings-FB01Q001/B-66112.LSUMZ.TISS-3:A1.Crypturellus-transfasciatus.R2.fq.gz ./
# this gets's the R1 (read 1) and R2 (read 2) files for this individual
# (B-66112.LSUMZ.TISS-3:A1.Crypturellus-transfasciatus) from S3 and
# saves them locally on your machine.This is rather cumbersome if you need a significant number of files or do not feel like browsing around the directory structure, so there is another way that you can browse, select files, and download a list of those files. We've setup an interactive spreadsheet of samples that you can browse, filter, etc. at https://www.openwings.org/data. Once you have selected the samples that you want, download the resulting CSV file. See the quick example in this short video of how you can select the sample data you want:
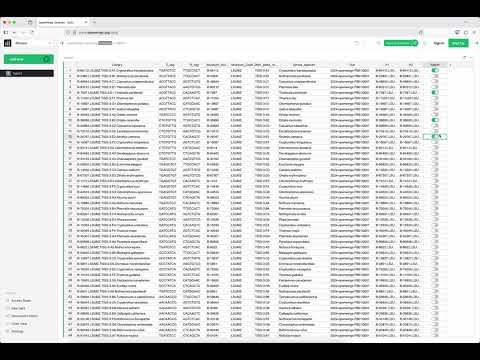
After you download the CSV file (it must be CSV), do not modify it and place it in the directory where you would like to store your data. Then, navigate to that directory on the command line, and run the following shell script (be sure you have installed the AWS CLI):
# Change this to the name of the file that you downloaded.
# This should be the default file name.
input="OpenWings-Libraries-Table1.csv"
# Do not edit below
# Store whatever IFS currently is (from Kusalananda on stackexchange)
unset saved_IFS
[ -n "${IFS+set}" ] && saved_IFS=$IFS
# Parse the file
while IFS=, read f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 f11;
do
echo "Working on ${f1}";
aws s3 cp s3://openwings-project/data/${f8}/${f9} ./;
aws s3 cp s3://openwings-project/data/${f8}/${f10} ./;
done < <( tail -n +2 "$input")
# Restore whatever IFS originally was
unset IFS
[ -n "${saved_IFS+set}" ] && { IFS=$saved_IFS; unset saved_IFS; }
# Do not edit aboveThis will iterate over every line in the CSV file you downloaded (skipping the header), and it will create and run the necessary commands to download the R1 and R2 files to the directory in which you run it. You should not need to install anything other than the AWS CLI for this to work on most Unix-like operating systems. If you are working on Windows, you can use the Windows Subsystem for Linux (WSL) to do the same.
Once you download the data, the easiest way to begin working with them is to follow the Phyluce Tutorial which describes how to process and analyze UCE sequencing data from the raw reads that you just downloaded. You should substitute the files that you have download for files that are used as examples in that tutorial.
The primary investigators of OpenWings request the right to publish studies using the data collected at taxonomic levels above order (e.g. interordinal and higher levels) and to infer and time-calibrate phylogenies for taxonomic levels above order as well as from all bird species before these data are used by other investigators for similar purposes. This is in keeping with the Ft. Lauderdale Agreement.
Following the general standard for the field of vertebrate phylogenetics/phylogenomics, please include a table listing the institution/museum code and the tissue/specimen number for each OpenWings sample that you use. Typically, such a table will also include the species name and other information associated with each sample. Files are named in a way that retains the primary bits of this information (see Data format).
Studies that use data generated by OpenWings should acknowledge support from the "OpenWings Project" and include references to the following National Science Foundation grants that supported this project:
| Grant #s |
|---|
| DEB-1655559 |
| DEB-1655624 |
| DEB-1655683 |
| DEB-1655736 |
We suggest something similar to the following text for inclusion in an Acknowledgements section (or similar) of a manuscript that uses OpenWings data:
Data used as part of this publication were generated by the OpenWings Project, which was supported by National Science Foundation grants DEB-1655559, DEB-1655624, DEB-1655683, and DEB-1655736.
We request that researchers using these resources provide us with information regarding their use of these data so that we can track the impact of this research project. Please complete the:
As we validate the individual data files and ensure that their taxonomic descriptions and sequence data are accurate, we will upload the data files to the NCBI SRA. Once this is done, we will update the metadata available from https://www.openwings.org/data to associate correct SRA identifiers with file names.
If you use these data in your research, please do not submit them, independently, to the NCBI SRA - you did not generate them.
- American Museum of Natural History (Brian Smith)
- Australian National Wildlife Collection (Leo Joseph)
- University of Minnesota / Bell Museum of Natural History (Keith Barker, Sushma Reddy)
- UW / Burke Museum of Natural History and Culture (Sharon Birks, Adam Leache, Alejandro Rico-Guevara)
- Bruce Museum (Dan Ksepka)
- Field Museum of Natural History (Ben Marks, Shannon Hackett, John Bates)
- LSU / LSU Museum of Natural Science (Brant Faircloth, Robb Brumfield)
- Moore Laboratory of Zoology (John McCormack)
- Museu de Zoologia da USP (Luís Fábio Silveira)
- National History Museum of Denmark (Peter Hosner)
- University of Florida (Rebecca Kimball, Ed Braun)
- University of Kansas Biodiversity Institute (Rob Moyle)
- NMNH, Smithsonian Institution, USGS Biological Survey Unit (Terry Chesser)
- University of Alaska Museum of the North (Kevin Winker)