Welcome to the Qwen-TTS repository. This project offers a powerful text-to-speech service built on the Qwen-TTS API. It supports both Chinese and English, along with various Chinese dialects. This FastAPI application aims to provide a seamless experience for users needing voice synthesis capabilities.
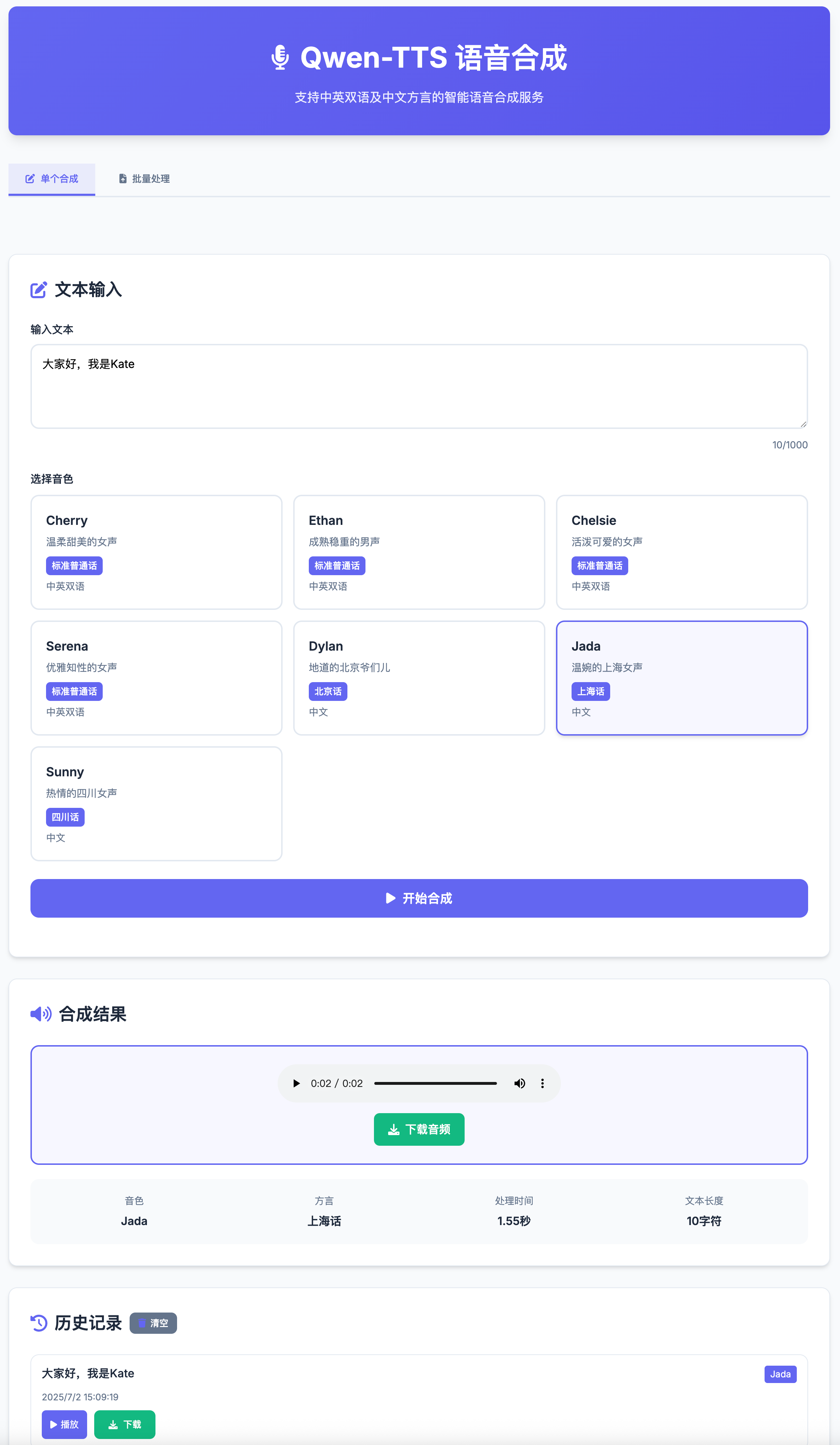
- Multi-Voice Support: Choose from 7 different voices, including options for both Chinese and English.
- Dialect Support: Includes Beijing, Shanghai, and Sichuan dialects.
- Real-Time Synthesis: Experience fast and responsive voice synthesis.
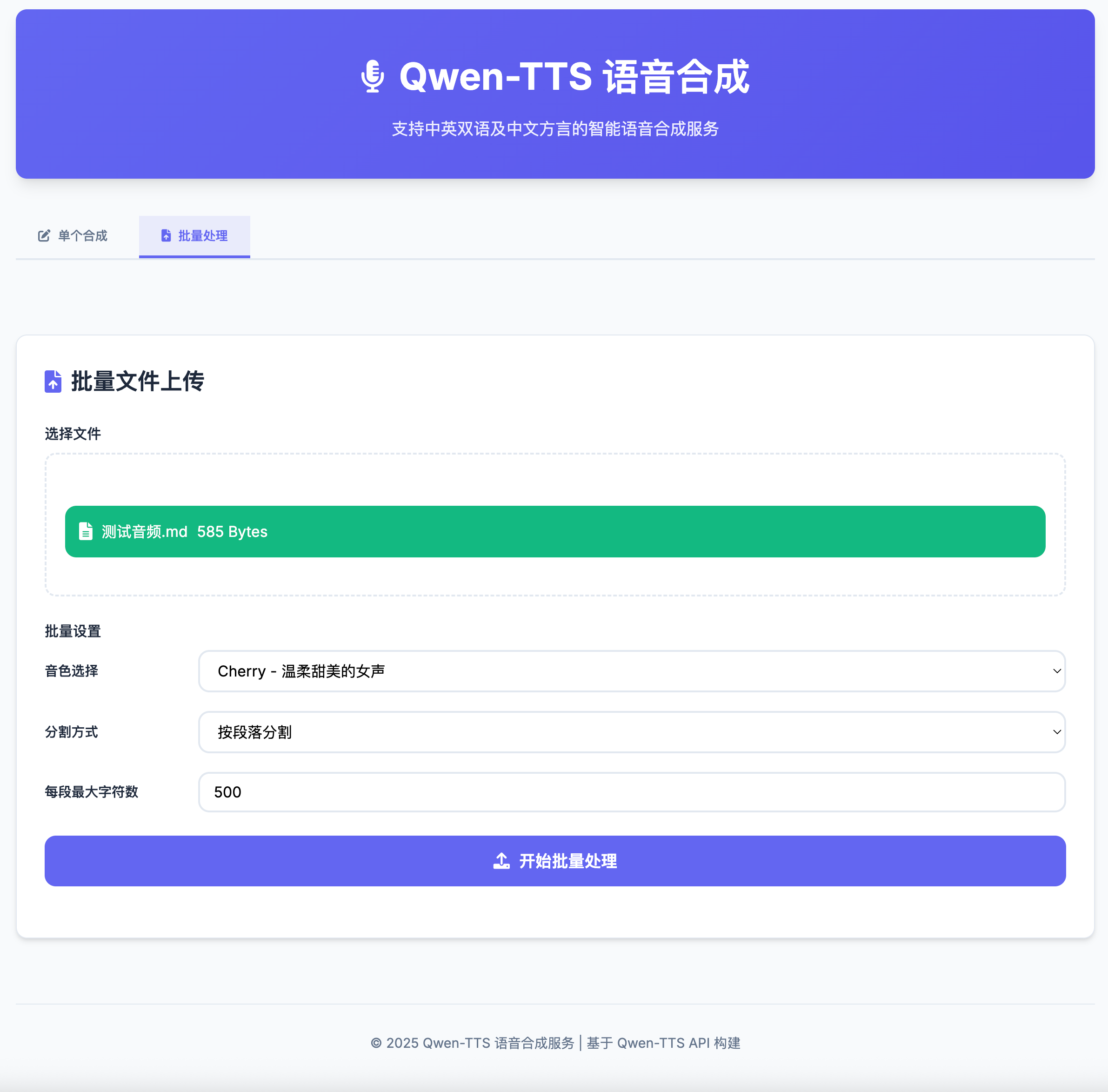
- Batch Processing: Upload and process txt/md files in bulk.
- Smart Segmentation: Automatically split text by paragraphs, sentences, or chapters.
- Progress Tracking: Monitor batch processing progress in real time.
- Audio Playback: Play and download audio directly from the interface.
- Audio Format: Outputs in WAV format for clear sound quality.
- Modern Design: A visually appealing and responsive user interface.
- Consistent Layout: Unified width (1200px) for both single synthesis and batch processing pages.
- Intuitive Operation: User-friendly experience for all users.
- History Tracking: Automatically saves synthesis history for easy access.
- Real-Time Feedback: Character count and status updates displayed live.
- Asynchronous Processing: High-performance asynchronous API for quick responses.
- Error Handling: Comprehensive error management to ensure smooth operation.
- File Management: Automatic management of audio files for convenience.
- API Documentation: Complete OpenAPI documentation available for developers.
| Voice | Language | Description | Dialect |
|---|---|---|---|
| Cherry | Chinese/English | Gentle and sweet female voice | Standard Mandarin |
| Ethan | Chinese/English | Mature and steady male voice | Standard Mandarin |
| Chelsie | Chinese/English | Lively and cute female voice | Standard Mandarin |
| Serena | Chinese/English | Elegant and knowledgeable female voice | Standard Mandarin |
| Dylan | Chinese | Authentic Beijing male voice | Beijing dialect |
| Jada | Chinese | Gentle Shanghai female voice | Shanghai dialect |
| Sunny | Chinese | Enthusiastic Sichuan female voice | Sichuan dialect |
To get started with Qwen-TTS, follow these steps:
- Download the Latest Release: Visit the Releases section to download the latest version of the application.
- Installation: Follow the installation instructions provided in the release notes.
- Run the Application: Execute the application to start using the text-to-speech features.
For detailed instructions, refer to the documentation provided in the repository.
- Python 3.8 or higher
- FastAPI
- Uvicorn
- Additional dependencies as listed in
requirements.txt
- Clone the repository:
git clone https://github.com/mco2004/qwen-tts.git cd qwen-tts - Install the required packages:
pip install -r requirements.txt
- Run the application:
uvicorn main:app --reload
You may need to configure certain parameters in a configuration file or environment variables. Check the repository for more details.
The Qwen-TTS API provides several endpoints for text-to-speech operations. Below are the main endpoints available:
- Endpoint:
/synthesize - Method: POST
- Description: Synthesize speech from a single text input.
- Endpoint:
/batch - Method: POST
- Description: Upload a file containing multiple texts for batch synthesis.
- Endpoint:
/voices - Method: GET
- Description: Retrieve a list of available voices and their details.
Refer to the API documentation for more information on request and response formats.
To synthesize speech from a single text input, send a POST request to the /synthesize endpoint with the following JSON body:
{
"text": "你好,欢迎使用 Qwen-TTS!",
"voice": "Cherry"
}To process multiple texts, upload a file to the /batch endpoint. The file should contain one text per line.
Comprehensive API documentation is available in the repository. This includes detailed descriptions of each endpoint, request/response formats, and examples.
- For the latest releases, visit the Releases section.
- Check the Wiki for more in-depth tutorials and guides.
We welcome contributions to improve Qwen-TTS. If you would like to contribute, please fork the repository and submit a pull request. Ensure that you follow the coding standards and include tests for new features.
For questions or feedback, please open an issue in the repository. You can also reach out via email or other contact methods listed in the repository.
Thank you to all contributors and users who support the development of Qwen-TTS. Your feedback helps us improve the application and provide better services.
Explore the capabilities of Qwen-TTS and enhance your projects with advanced text-to-speech functionalities.