
This repository contains the official Python package for CREPE — a fast, interpretable, and clinically grounded metric for automated chest X‑ray report evaluation.
# Python >= 3.9
pip install --upgrade pip
pip install "torch>=2.1" "transformers>=4.41"This repo is a small Python package; you can import it directly from the project root (editable install optional).
The default checkpoint is hosted on the Hugging Face Hub (
gihuncho/crepe-biomedbert) and will be downloaded on first use. If your environment has restricted internet access, pass a localcache_diror model path (see below).
import torch
import crepe
# (optional) set a cache directory for HF model files
cache_dir = "your/path/to/cache/dir"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1) Load model & tokenizer (defaults to gihuncho/crepe-biomedbert)
model, tokenizer = crepe.load_model_and_tokenizer(cache_dir=cache_dir)
model.to(device).eval()
# 2) Score a pair of reports
reference = "Normal chest radiograph"
candidate = "Bilateral pleural effusions noted"
result = crepe.compute(
model=model,
tokenizer=tokenizer,
reference_report=reference,
candidate_report=candidate,
device=device.type, # "cuda" or "cpu"
)
print(result)
# {
# "crepe_score": <float>, # lower is better
# "predicted_error_counts": [nA, nB, nC, nD, nE, nF] # continuous, >= 0
# }Tokenization uses pair encoding:
(reference, candidate), with truncation/padding to 512 tokens to match the training setup.
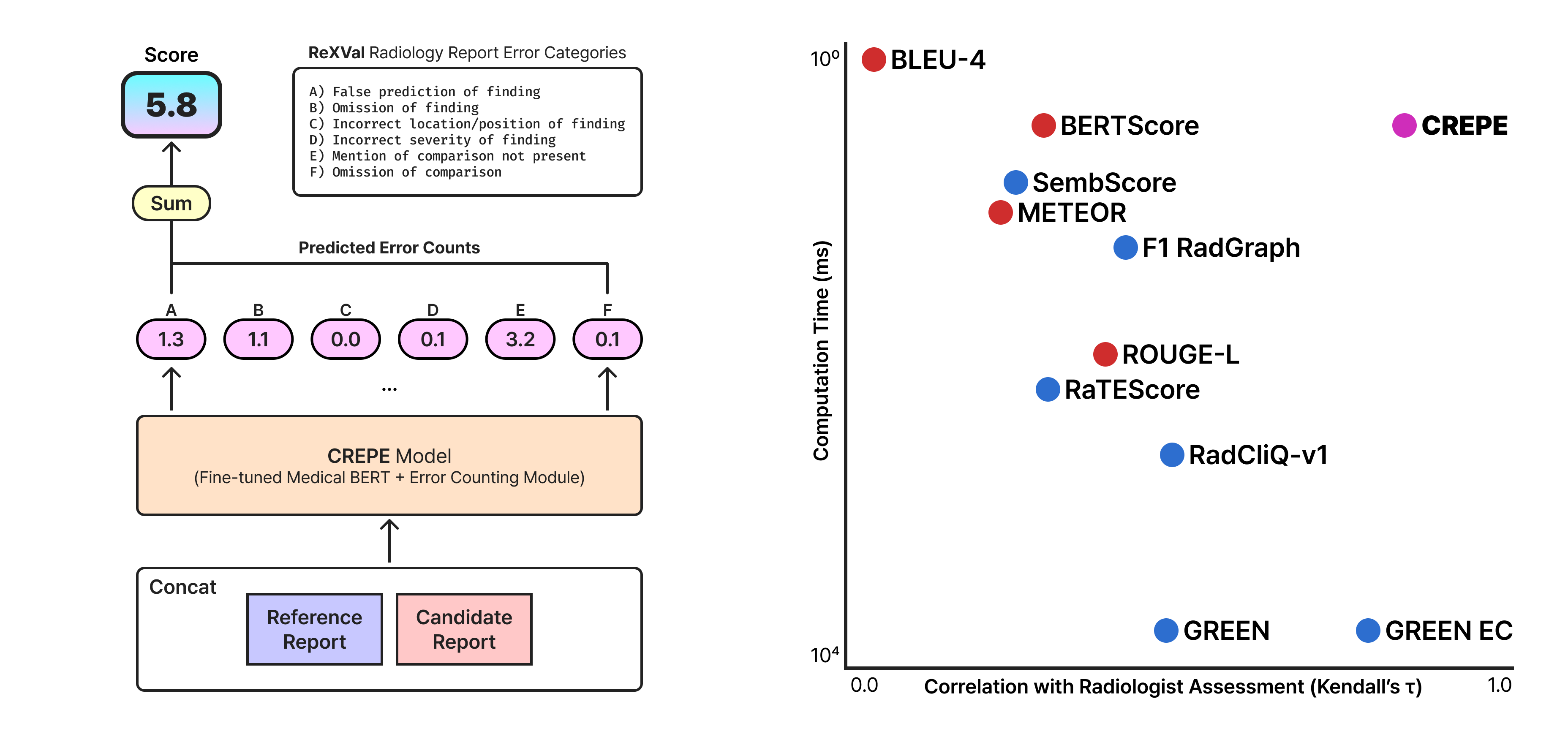
predicted_error_counts: a list of six non‑negative floats[nA, nB, nC, nD, nE, nF], ordered by categories A→F as defined above. Values are continuous (not forced to integers).crepe_score: the unweighted sum of the six predicted counts. Lower is better (fewer predicted discrepancies).
# crepe.__init__.py
load_model_and_tokenizer(model_name_or_path="gihuncho/crepe-biomedbert", cache_dir=None)
# -> (model, tokenizer)
compute(model, tokenizer, reference_report, candidate_report, device="cpu")
# -> {"crepe_score": float, "predicted_error_counts": List[float]}Advanced utilities (optional):
# crepe.models.get_model_and_tokenizer(ckpt_path, device=None)
# crepe.models.get_predicted_counts(model, tokenizer, gt, pred, device=None)Under the hood, the model is a
PreTrainedModelwith six regression heads; auxiliary presence heads exist for training but are not used at inference. Predictions are clipped to be non‑negative. Seecrepe/models.py.
If you have any questions, feel free to contact!
@inproceedings{cho-etal-2025-crepe,
title = "{CREPE}: Rapid Chest {X}-ray Report Evaluation by Predicting Multi-category Error Counts",
author = "Cho, Gihun and
Jang, Seunghyun and
Ko, Hanbin and
Baek, Inhyeok and
Park, Chang Min",
editor = "Christodoulopoulos, Christos and
Chakraborty, Tanmoy and
Rose, Carolyn and
Peng, Violet",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.1102/",
pages = "21749--21766",
ISBN = "979-8-89176-332-6"
}