你好,我是小一
今天的实战项目是一个比赛项目,小一我通过分析和建模杀入了Top10%
害,相比起网上一搜一堆Top5%的,小一的结果确实有点......
不过,这也没什么,谁还不是一步步过来的呢,只要我一直在路上,我就离成功更进一步。
今天的内容相比起上篇的精简了很多《吊打分析师》实战—我要租个好房
其实主要是太懒(手动狗头)
做一下必要的介绍:
- 小一使用的Python版本是3.8
- 开发环境是Pycharm2019.3
- 图形可视化使用matplotlib+seaborn
为了显示美观,部分截图是在Jupyter 下运行的结果,大家不用纠结
ok,开始我们今天的实战
今天的项目有一个很凄美的背景:
世界上最大的豪华客轮,被称为永不沉没的梦幻客轮的“泰坦尼克号”,在它的处女航上却被大自然的神秘力量打败。
由于救生艇的数量不足,在客轮撞上冰山的紧急时刻,船长冷静下令:女士和小孩先走,请把机会让给她们。
在生与死面前,人们会听从船长的命令还是会各自逃命?
在海难的最后,什么样的人最终幸存下来了?
在每一个生命的背后,生还与遇难又有着怎样的特征规律?
依稀记着这部电影是小一看的第一部大片,当时那会还在读小学,一转眼就是十几个春夏秋冬,还记得那会...
好了好了,收~
了解了背景之后,结合上面的三个问题,抛开灵魂层次的抨击,我们需要考虑下面几点:
- 生还与遇难是完全看运气吗?
- 什么样的人生还几率较大?反之?
- 生还与遇难与什么有关?与什么最相关?
- 如何准确的预测生还者情况?
可能看完这几个问题你脑海里已经有了几分答案,究竟是与不是呢?
在往下看之前,先稍停一会,考虑一下如果是你,这几个问题应该怎么去分析?
在分析上面的问题之前,小一给出了以下的参考建议:
- 生还与遇难的总体分布
- 单特征下整体结果的分布
- 多特征下整体结果的分布
- 每个特征的得分情况
小一哥,说了半天,我们的数据是什么样的?
能够在现在才开始问这个问题,进步了!
敲黑板:
在拿到一个任务之前,首先要做的一定是了解问题、分析问题,不是上来就先看你的数据是怎样的。
我们不是针对数据去讨论结果,我们是针对问题去取数据,通过数据去验证、去预测。
再来说我们的数据,一共有两份数据。
第一份数据中有每个人的相关信息(具体字段见下文),以及最终的生还情况。
第二份数据只有相关信息,需要我们进行预测生还情况(PS:Kaggle比赛题目数据)
数据预处理的目的是什么?
拿到一份数据,我们必须要确保数据的规整,方便后面的可视化和预测都能顺利展开
总的来说,数据预处理包括:缺失值处理、重复值处理、异常值处理和数据重塑转换等
先来看一下我们今天的数据
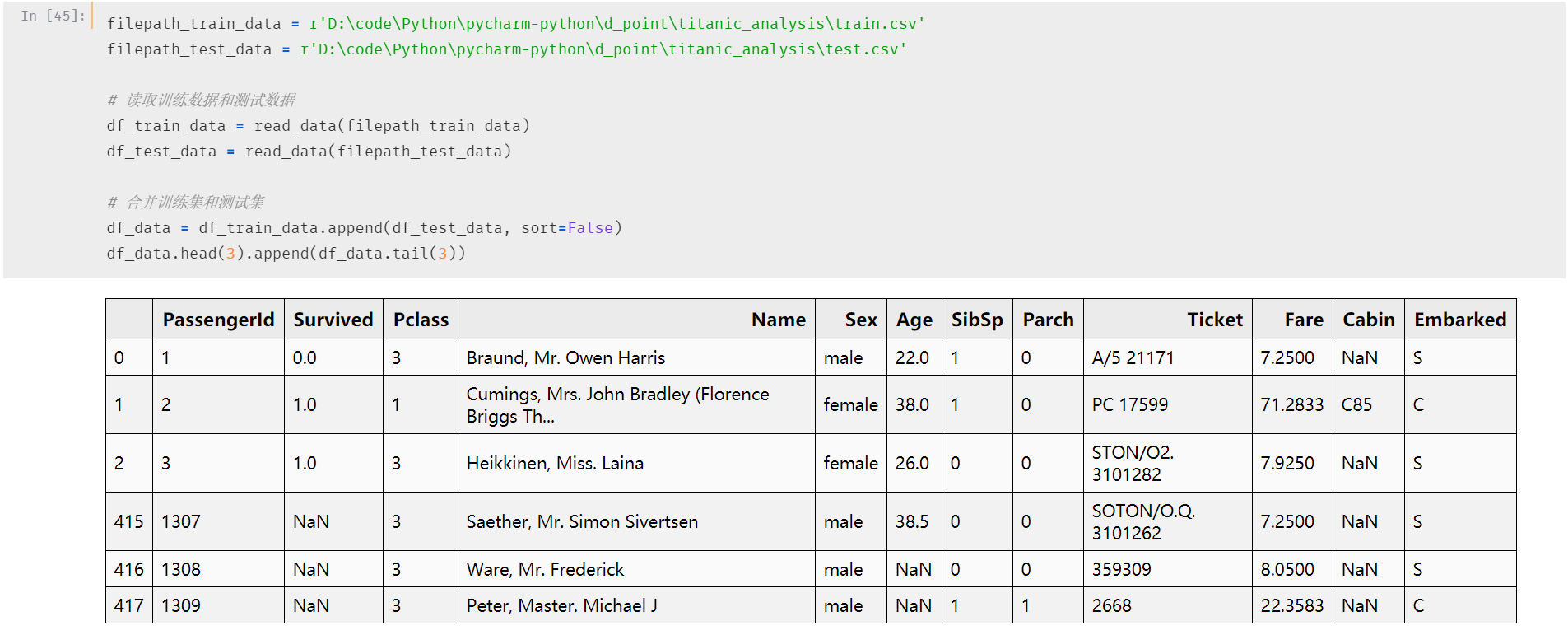
数据中共有12个字段,测试数据没有标签列(Survived)。
看一下详细的字段含义:
数据特征:
PassengerId: 乘客ID
Pclass: 乘客等级(1/2/3等舱位)
Name: 乘客姓名
Sex: 性别
Age: 年龄
SibSp: 堂兄弟/妹个数
Parch: 父母与小孩个数
Ticket: 船票信息
Fare: 票价
Cabin: 客舱
Embarked: 登船港口
目标信息:
Survived: 生还
12个字段都是什么类型呢?缺失情况又是什么样的?
一起来看一下:
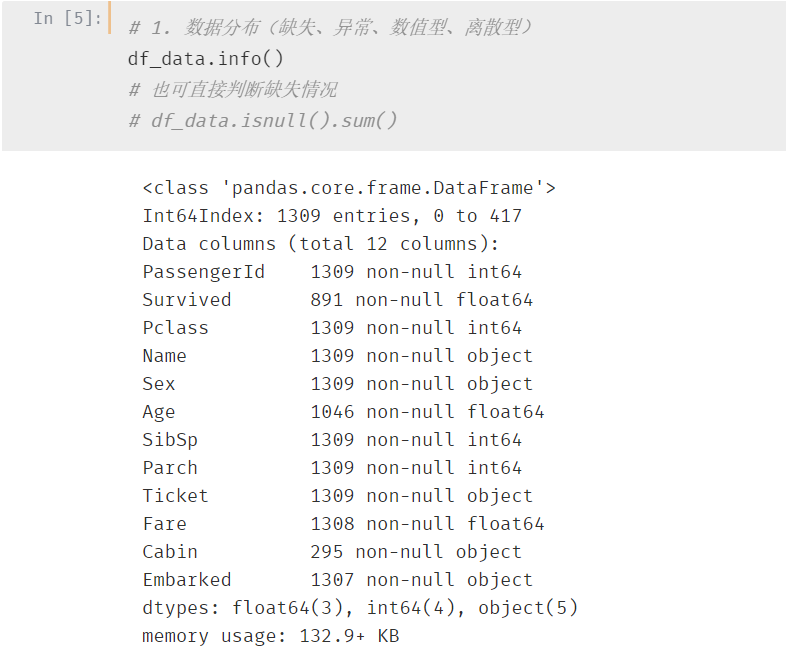
通过Survived 标签列可以看出一共891条训练数据
其中,数值型数据(int、float类型)包括:PassenegerId(乘客id)、Survived(生还or遇难)、Pclass(船舱1/2/3)、Age(年龄)、SibSp(堂兄弟/妹个数)、Parch(父母与小孩个数)、Fare(票价)
但是实际上Pclass、Survived属于类别数据,这里只是通过1/2/3去表示类别,需要注意嗷
总体数据中,Age、Fare、Cabin 和Embarked 均存在不同程序的缺失
为什么要单独挑出数值型数据呢?
我们可以针对数值型数据,查看数据的统计情况
通过describe 看一下
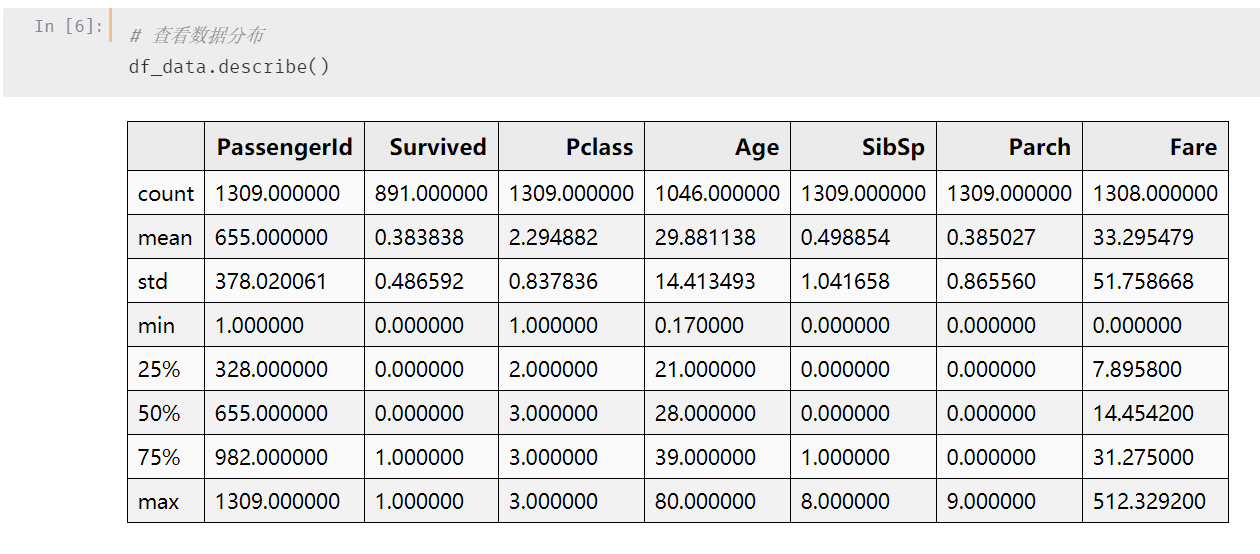
稍微分析一下,其中:
-
Pclass:最小值为1,最大值为3,均值为2.3,说明3等舱位的应该是多数
-
Age:最小值为0.17,最大值为80,均值为29.88,最大最小值需要再观察一下
-
Fare:最小值为0,最大值为512,std为51,波动较大,需要注意
整体数据就是这样,接下来我们进行详细的清洗操作
为什么要进行字段分析,不是要进行数据预处理吗?
分析具体的字段含义,更有利于我们进行缺失值的填补,所以这里放在了第一步
Name 列数据是通过逗号分隔开(即姓+名),姓氏似乎可以帮我们做一些事情
例如:同一姓氏的人可能是一个小团体,所以,我们将姓名进行分离
# 将名和姓分离
df_data['last_name'] = df_data['Name'].apply(lambda name: name.split(',')[0])
df_data['first_name'] = df_data['Name'].apply(lambda name: name.split(',')[1])拆分出来后name 数据变成了三列
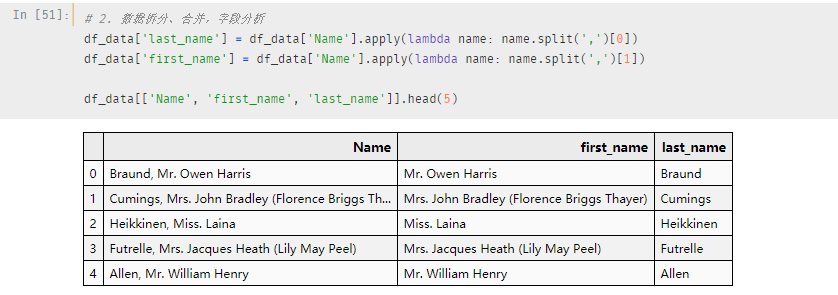
似乎姓氏前面的title 也有一种特别的含义,但是小一只知道Miss.和Mrs.,还是从英语课上学的
不懂就问呗,小一在狂补了自己的英语之后,才发现数据中的称呼竟然是这样的:
Mr:Mister缩写,指先生
Miss、Mlle、Ms:都表示女士(未结婚或没有子女之类的)
Mrs、Mme:指夫人(亦指已婚妇女)
Master:少爷(小一猜指小孩)
Rev:牧师
Dr:医生
Capt、Col、Major:上校、中校、少校(小一猜想应该属于船上的船长、副船长这类人员,所以分为一类)
Don、Dona、Sir(先生、女士。指贵族和有地位者)
Jonkheer、Countess、Lady:乡绅、伯爵(亦指有地位者)
这么多称呼,难道分为这么多类别?
也不是不可以,但是针对本项目的背景,小一觉得应该这样划分:
- 普通人士,分为男士和女士
- 特征职业的人士,比如船员、医生、牧师,因为是海难,所以船员可单独分类
- 有地位者、贵族等
综上啊,我们可以分为下面这几类
Mr:指男士
Miss、Mlle、Ms、Mrs、Mme:指女士
Rev、Dr::牧师、医生
Capt、Col、Major:船员等
Master、Don、Dona、Sir、Jonkheer、Countess、Lady:有地位者
确定了分类标准,我们实际操作一下
①通过正则表达取出title 数据
# 通过正则表达式分离出名称前面的title标识
df_data['Title'] = df_data['first_name'].apply(lambda first_name: re.search('([A-Za-z]+)\.', first_name, flags=0).group(1))②通过分类标准对title 数据进行分类
# title 映射
title_mapping = {'Mr': 1, 'Miss': 2, 'Mlle': 2, 'Ms': 2, 'Mrs': 2, 'Mme': 2,
'Rev': 3, 'Dr': 3, 'Col': 4, 'Major': 4, 'Capt': 4,
'Master': 5, 'Don': 5, 'Dona': 5, 'Lady': 5, 'Countess': 5, 'Jonkheer': 5, 'Sir': 5,
}
# 将Title直接量化
df_data['TitleType'] = df_data['Title'].map(title_mapping)另外,在查称呼的时候小一看到一种有趣的说法
大概意思是:名字越长,表示家庭底蕴越丰厚,所以,地位也就越高。
这个标准靠谱吗?
靠不靠谱现在我们并不知道,可以在可视化部分通过观察指标之间的关联度去确定。
我们直接通过len 函数获取每个名字的长度
# 新增名字长度列
df_data['Namelen'] = df_data['Name'].apply(lambda name: len(name))现在我们的Name 列扩展成这样子
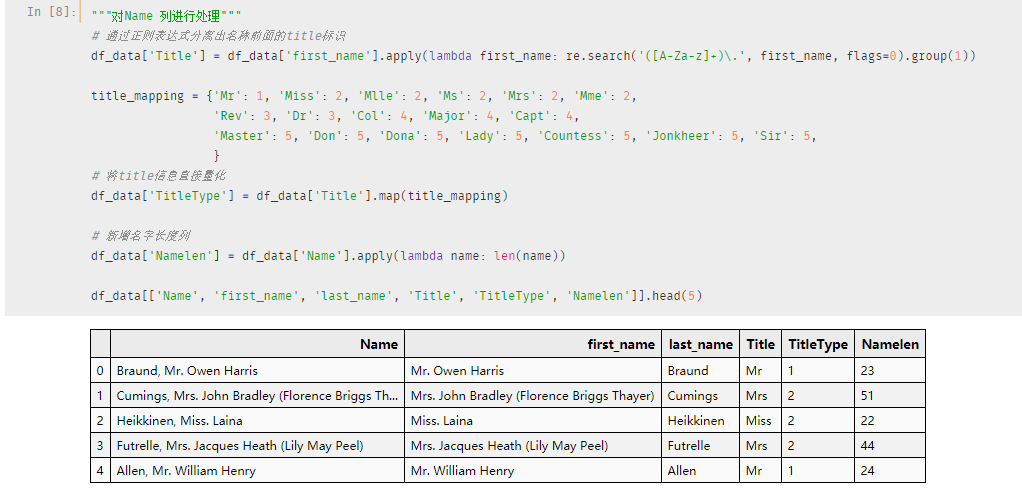
另外,上面提到的小团体概念我们也可以根据字段进行分类
这里根据每个人的SibSp 和Parch 数值代表这个团体的人数
# 家庭成员数:+1 表示加上自己
df_data["Numbers"] = df_data["SibSp"] + df_data["Parch"] + 1再来回顾一下到底有哪些数据需要填充?
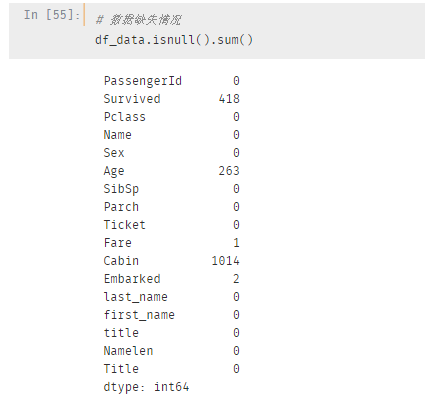
其中Age(缺失263)、Fare(缺失1)、Cabin(缺失1014)、Embarked(缺失2),下面来对缺失数据挨个处理
Fare缺失填充:根据缺失特征进行填充
这里缺失特征是:S登船港口3等船舱的 Storey, Mr. Thomas,年龄是60.5岁,家庭团体只有他一个人
填充方式:选择S登船港口3等船舱年龄大于60岁的平均票价填充

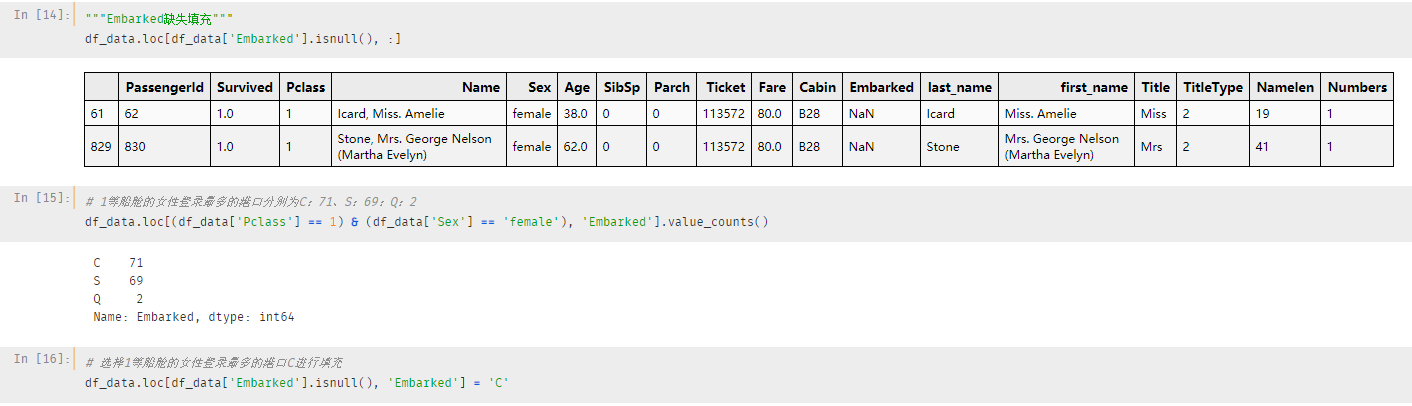
Embarked 缺失填充:同样的根据缺失特征进行填充
这里缺失特征是:1等船舱的B28客舱的两位女士,一个38岁,一个62岁
填充方式:选择1等船舱的女性登录最多的港口进行填充
Age 缺失填充:小一这里使用比较简单的一种填充方法
填充方式:使用同等舱位、同一登船港口、同一性别的众数/均值进行填充
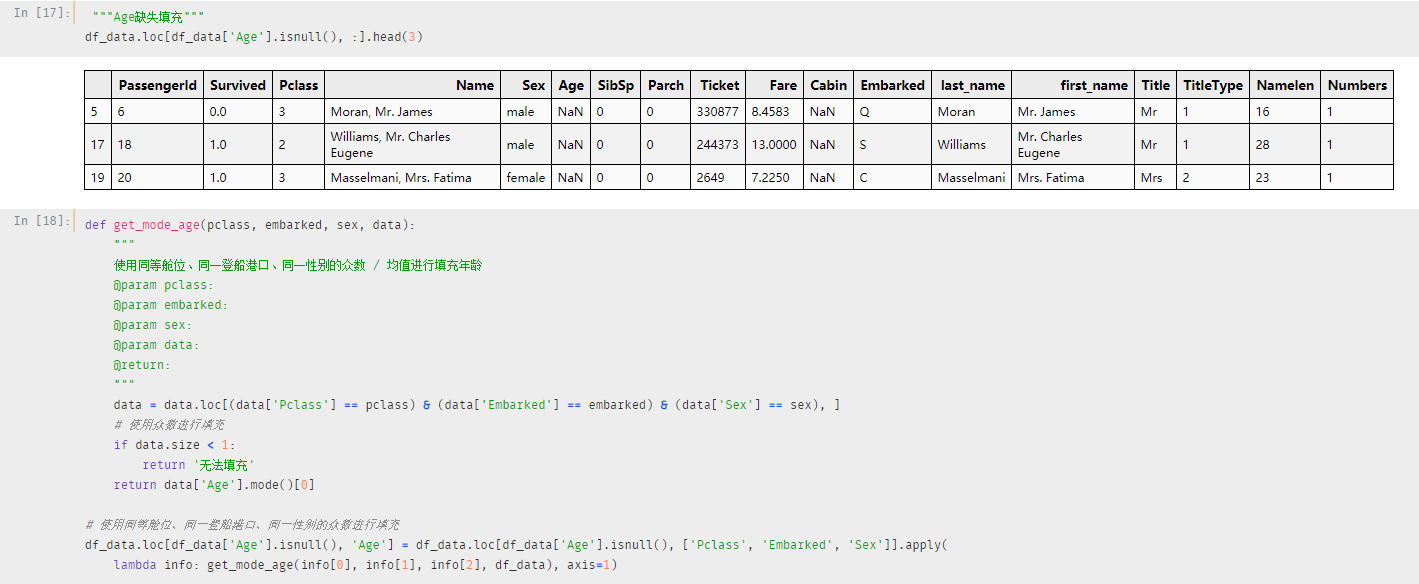
这个你可以进行优化,这种填充方法比较low
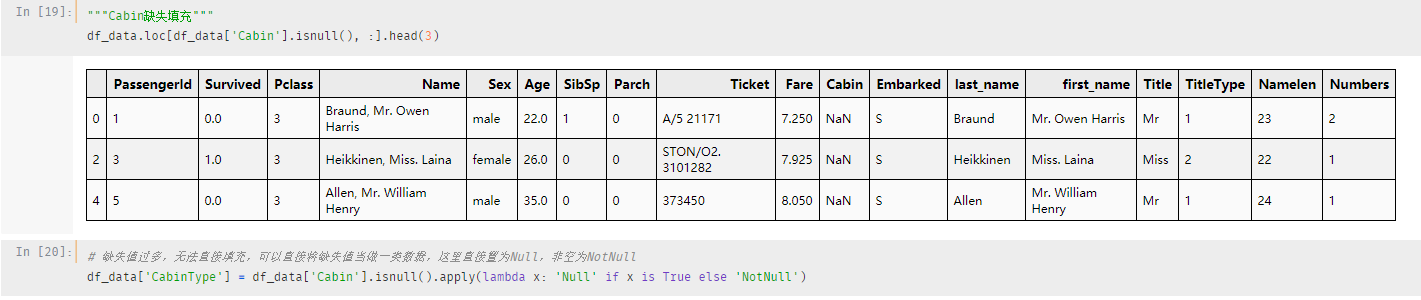
Cabin缺失填充
缺失值过多,填充的时候并不能保证我们填充的是否正确,反倒不如将空数据当作一类,非空的当作一类
填充方式:缺失值当做直接置为Null,非空为NotNull
今天的数据应该怎么去可视化呢?
在问题分析小节,我们确定了可以从单一特征、多特征去可视化探索数据,那我们就从这两个维度去分析
需要注意的是,对数值型数据和离散型数据的可视化要特别注意
如果是类别较少的离散性数据,我们可以分析每个类别的占比,如果是数值型数据,我们可以分析数据的分布范围
先来看看我们现有的数据特征:
"""
确定定性、定量数据
定性数据包括:定类数据和定序数据,主要包括以下字段:
PassengerId:乘客id
Survived:生还or遇难
Pclass:船舱等级
Name:乘客姓名
Sex:性别
SibSp:堂兄弟/妹个数
Parch:父母与小孩个数
Ticket:船票信息
Cabin:客舱
Embarked:登船港口
CabinType:客舱的分类(新增)
last_name & first_name & Title(新增姓名衍生列)
Title:姓名的title标识(新增)
Title_type:Title的分类(新增)
Namelen:姓名的长度(新增)
Numbers:家庭成员数(新增)
title_rank:姓名的title标识分类(新增)
定量数据包括:定距数据和定比数据,主要包括以下字段:
Age:年龄
Fare:票价
"""稍微分析一下:
- Pclass、Sex、SibSp、Parch、Embarked类别较少,可以进行条形图可视化
- Age、Ticket为离散数据,可以用折线图、散点图可视化
离散型单特征分析的目的是什么呢?
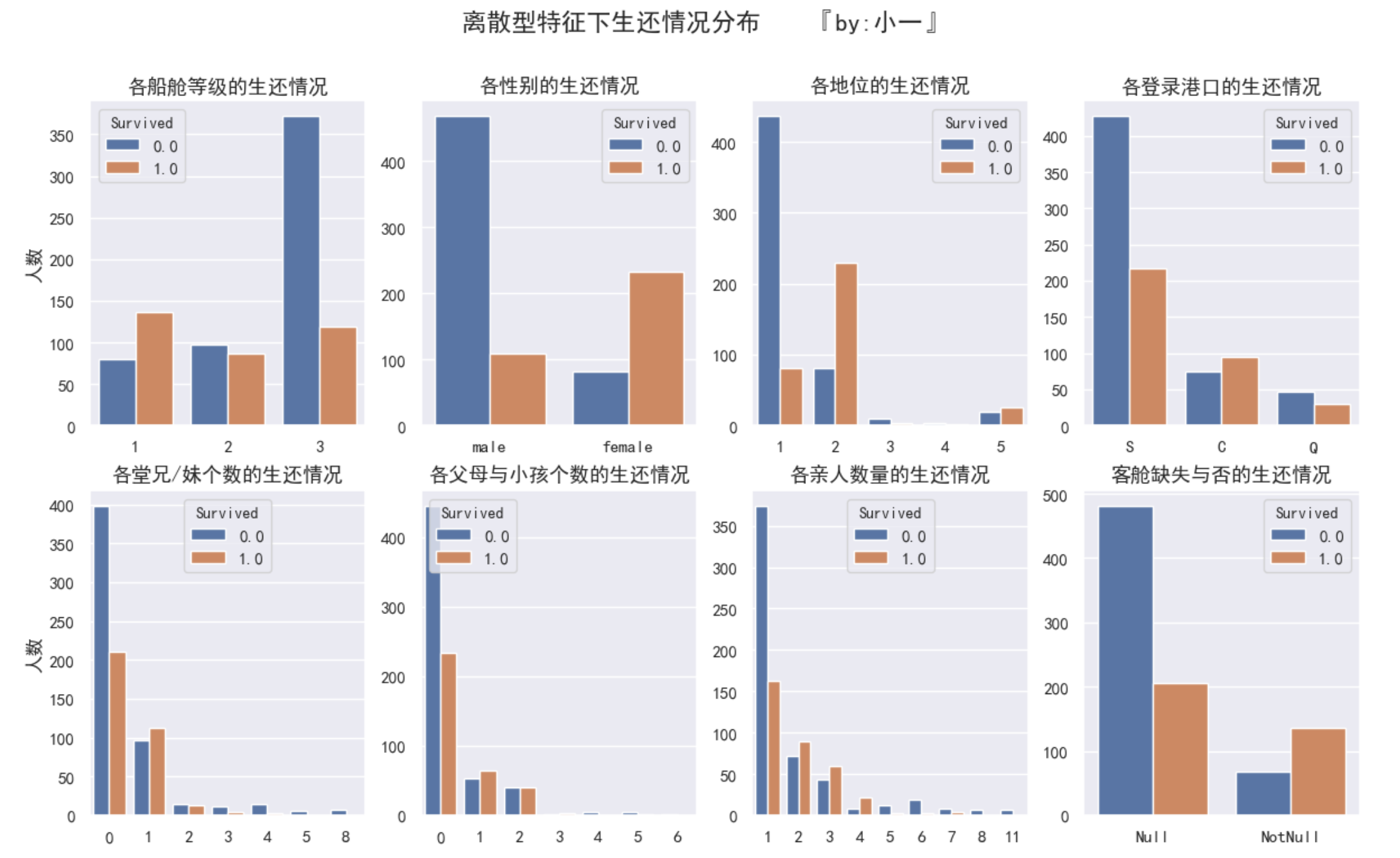
这一步的目的是分析每个特征是否会影响生还率,这也是我们刚开始就提出的小问题
你可以带着这个问题去看图
-
船舱等级为1的生还率最高(生还率0.7),等级3最低(不足1/3),但是等级3的人数最多
-
女性的生还率较高(超过2/3),但是男性人数远大于女性
-
地位为2、5的生还率高于死亡率,2和5分别对应:女士和有地位者
-
登录港口为C的生还率最高(超过1/2),S的最低(1/3),但S的人数最多
-
堂兄弟/妹个数为1的生还率最高(超过1/2),为0的样本最多
-
父母和孩子个数为1和2的生还率最高(超过1/2),为0的样本最多
-
亲人数量为2、3、4的生还率高于死亡率,只有自已一个人的团体最多,生还率低(不足1/3)
-
客舱非空的生还率高于客舱为空的
上面这些都是我们可以从图中得出的数据,根据这些小节我们还可以大胆推测一下:
- 船舱等级为3的人数最多,生还率最低,所以等级3为多为普通阶层?
- 女性生还率大于男性,所以C登陆港口女性居多?
- 亲人数量字段Numbers 可以代替SibSp 和Parch?
数值型数据只有两个:年龄和票价
可以通过它们的 kde 图看看具体数据分布
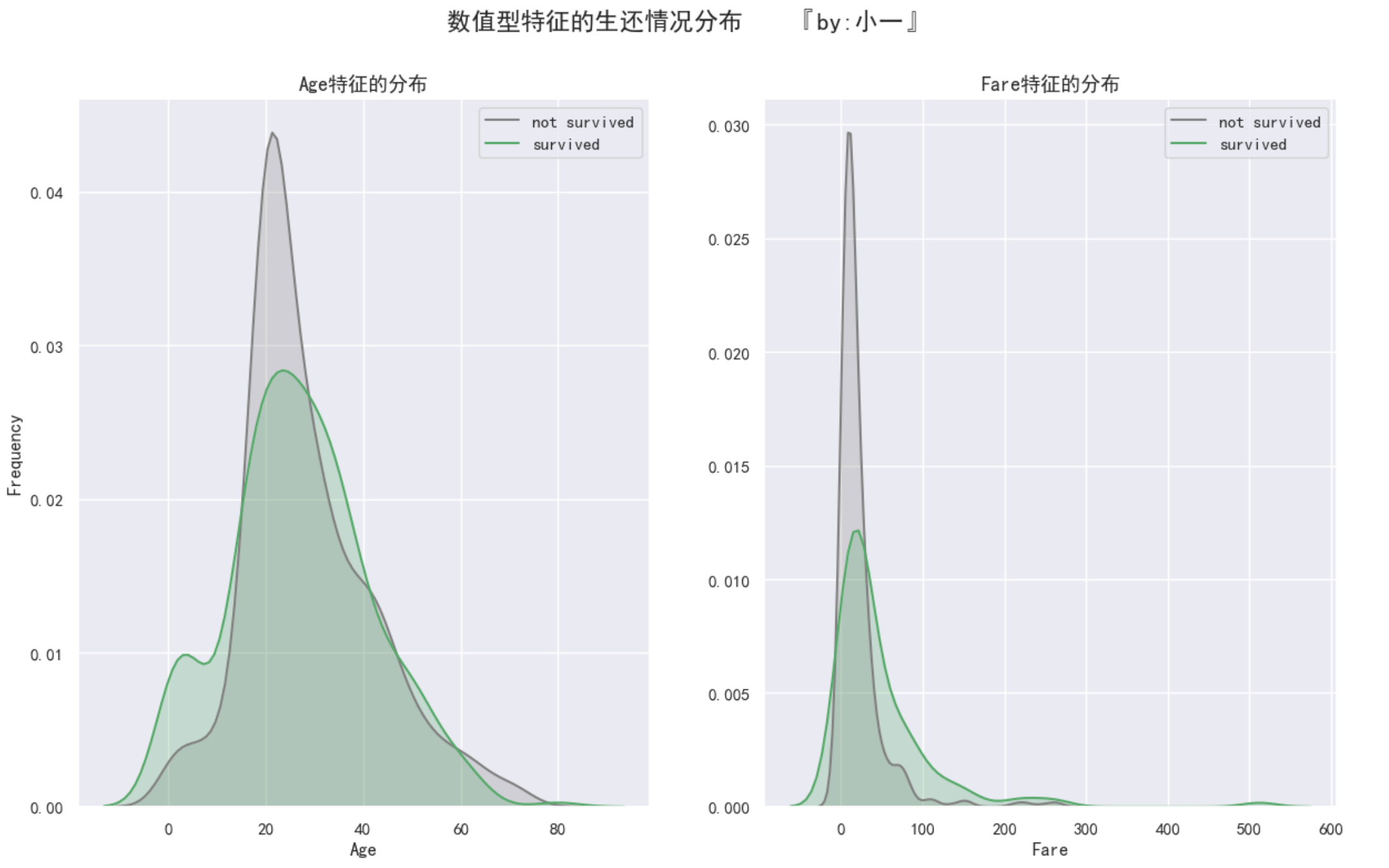
-
通过离中趋势得出中年人占据多数,年龄段在15-47
-
通过存活率得出儿童存活率高,儿童和中年人的年龄段分割点是15岁
-
通过离中趋势得出票价在0-100较多
-
通过存活率得出30是分界点,票价高于30,生还率大于死亡率
需要注意的是,票价的分布过于分散,后期考虑进行进一步处理
多特征联合是怎么联合的?
联合考虑多个特征之间的关联性
我们知道一件事情的发生会有多个因素的影响,同样的道理,生还与遇难也会由多个特征共同决定的
例如:不同船舱等级的男女分布,不同登船港口的年龄分布等,在这些分布下生还与遇难又会是什么样的
听着会比较绕,看图就好
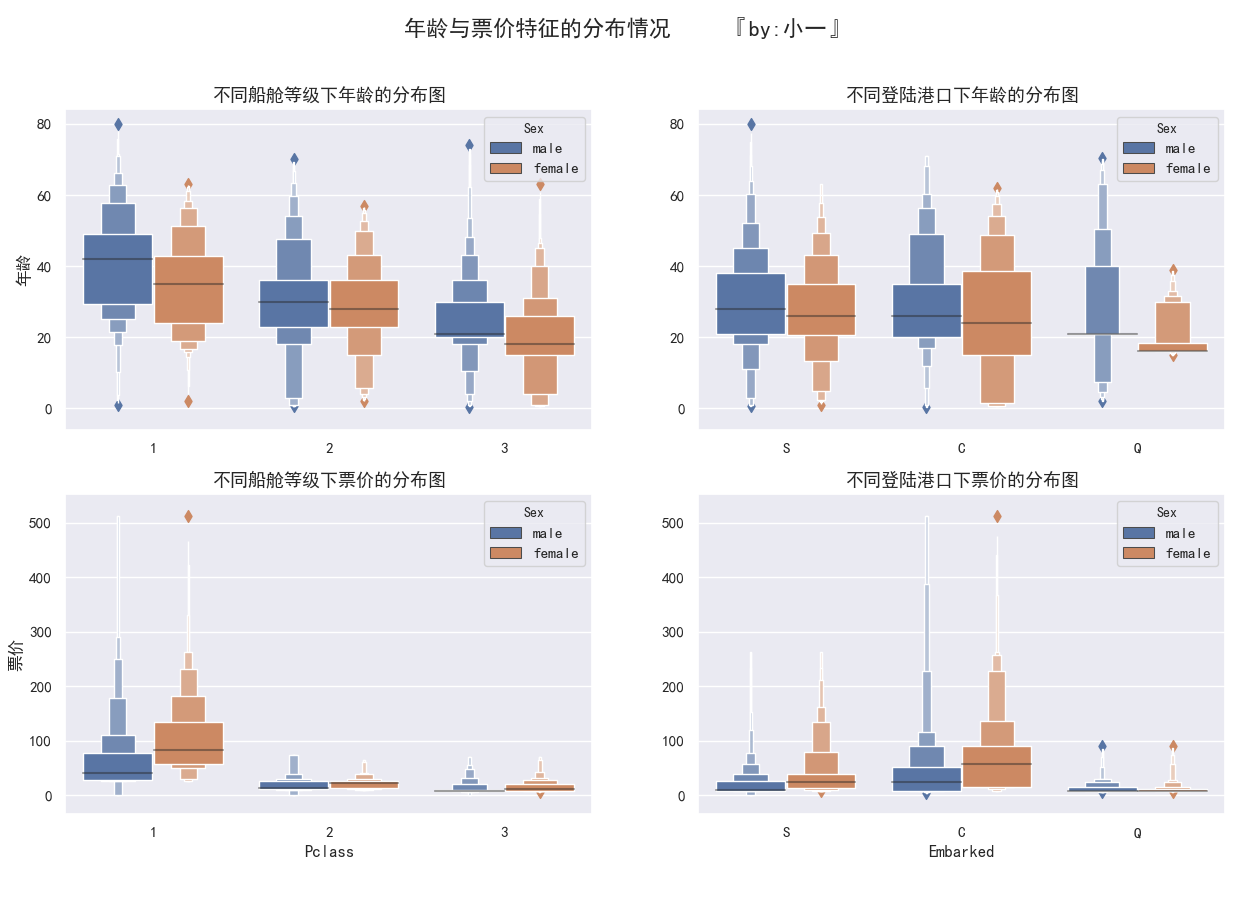
- 年龄中位数分布大致为 Pclass1>Pclass2>Pclass3
- 男性年龄中位数大于女性
- 船舱等级为1的票价较高,C登陆港口的票价稍高
- 女性的票价稍高于男性
结合1 中结论,可以推断出:
- Pclass1为中上层人士,年龄稍大;而Pclass3为底层青年,年龄稍小
- C登陆港口票价极有可能是女性贵族专用
继续看图:
Sex,Pclass分类条件下的 Age与Survived的散点分布图
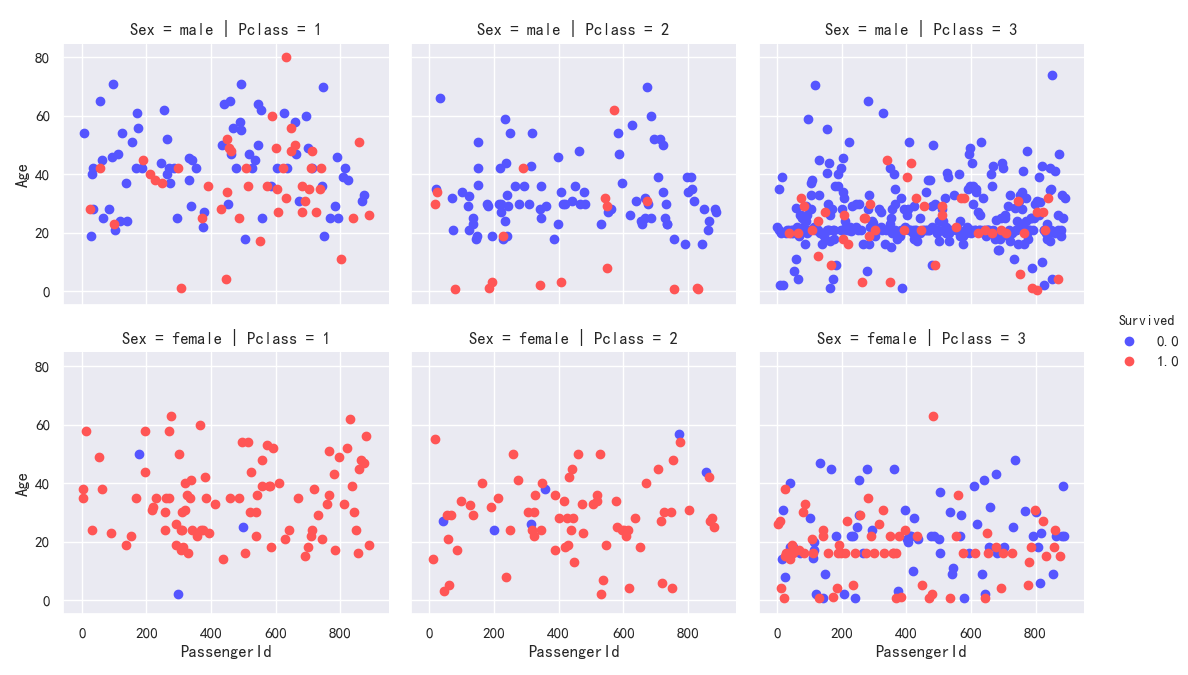
船舱等级为1和2的女性生还率最高
等级为1的男性生还率高于等级为2、3的男性
Sex,Embarked分类条件下的 Age与Survived的散点分布图
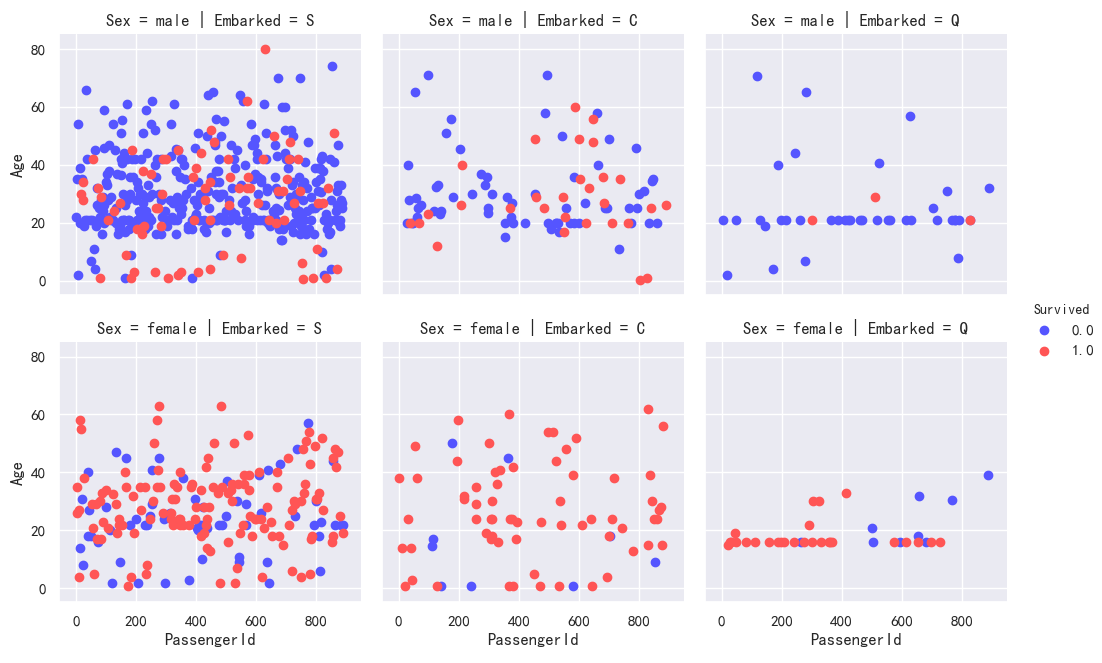
登陆港口为C的女性生还率最高,S、Q次之
登陆港口为Q的年龄分布主要在18~20之间
Embarked,Pclass分类条件下的 Age与Survived的散点分布图
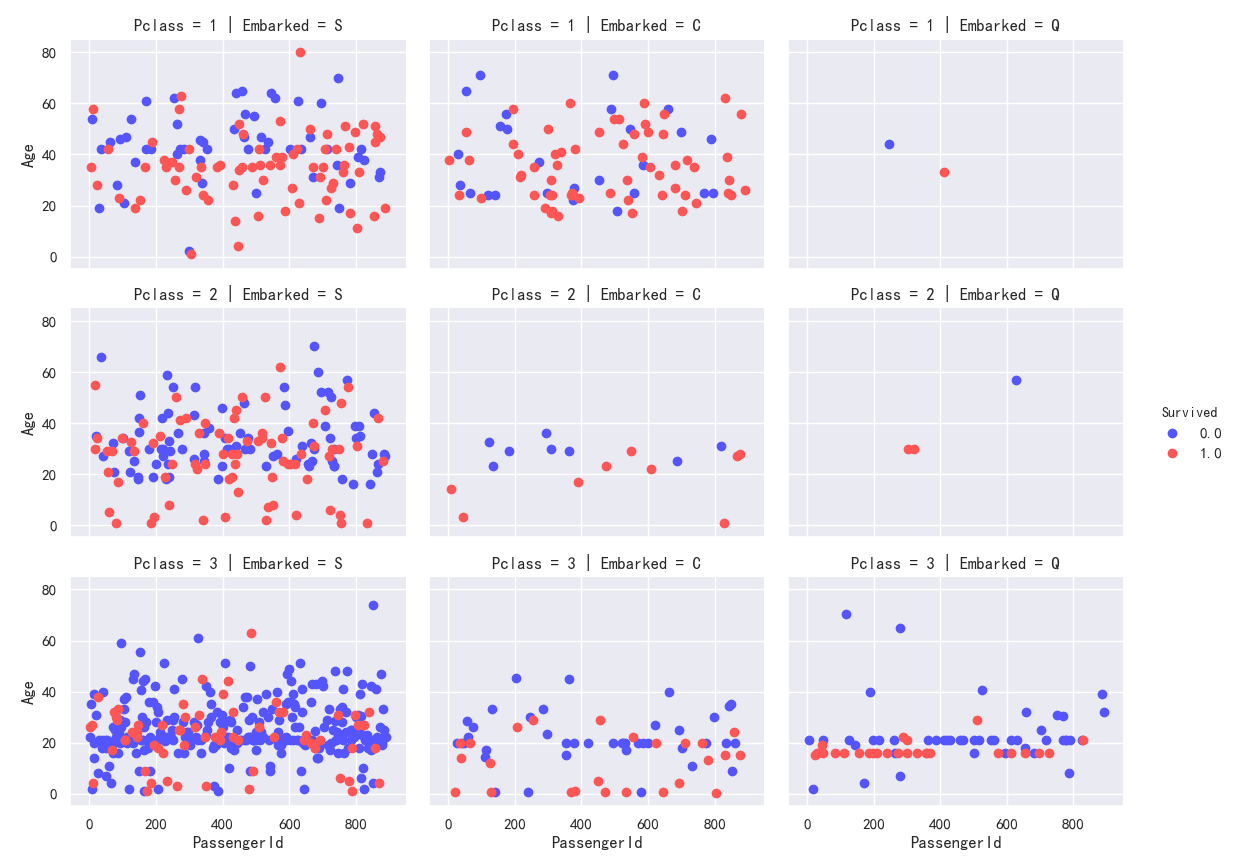
Q登陆港口的人数偏少,且主要是船舱3的人登陆
Embarked,Pclass分类条件下的 Fare与Survived的散点分布图
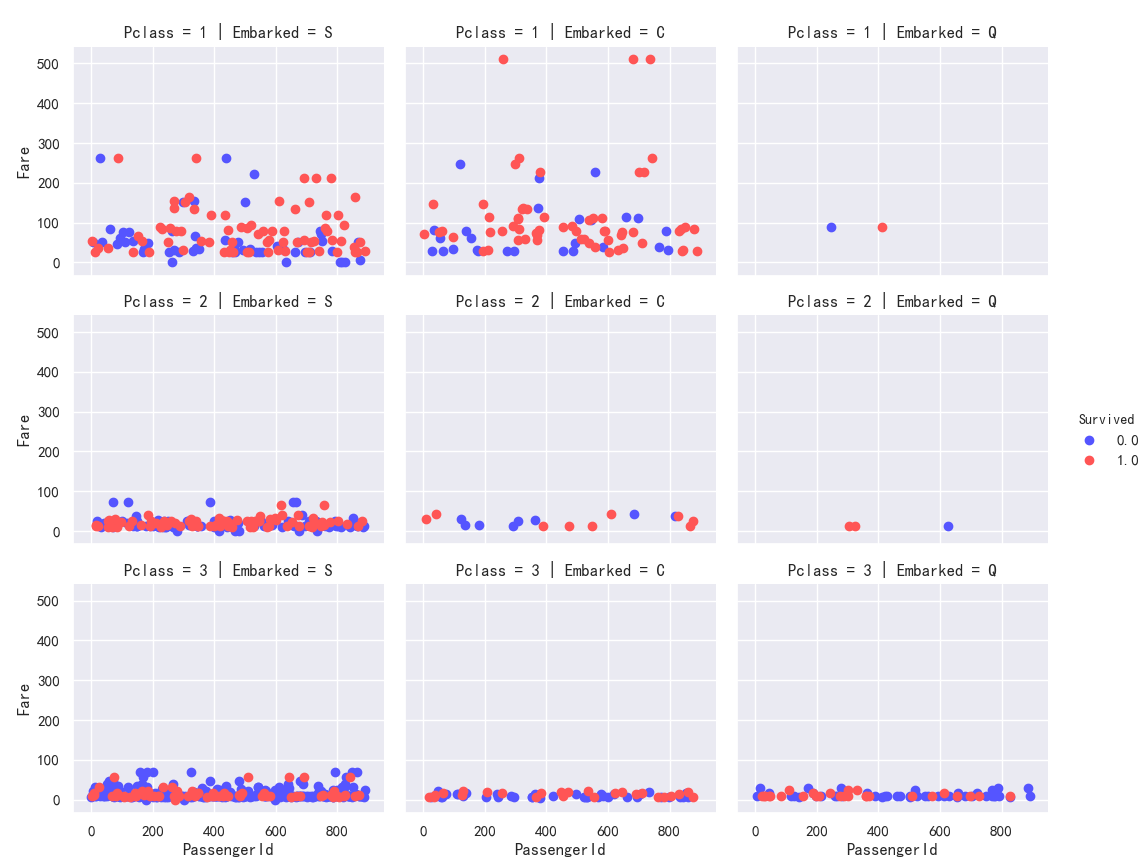
船舱等级为2和3的票价分布都在100以下
3个票价为500+(最高)的乘客最终都幸存了
总结一下上面四张图的结论:
- 船舱等级为1男性、女性生还率高于其他
- 女性生还率普遍高于男性
- C登陆港口的女性居多
- Q登陆港口人数较少,年龄分布主要在18~20
- 船舱等级为2和3的票价分布都在100以下,低于船舱等级1
我们从图中可以分析出结论还是挺多的,那究竟哪些特征比较重要呢?
希望你还记着这个名词:相关系数
Python实现相关系数特别简单,搭配seaborn 就有了下面这张热力图
"""通过画图进行特征选择"""
sns.heatmap(df_data.corr(), linewidths=0.1, vmax=1.0, square=True, cmap=sns.color_palette('RdBu', n_colors=256),
linecolor='white', annot=True)
plt.title('the features of corr')
plt.show()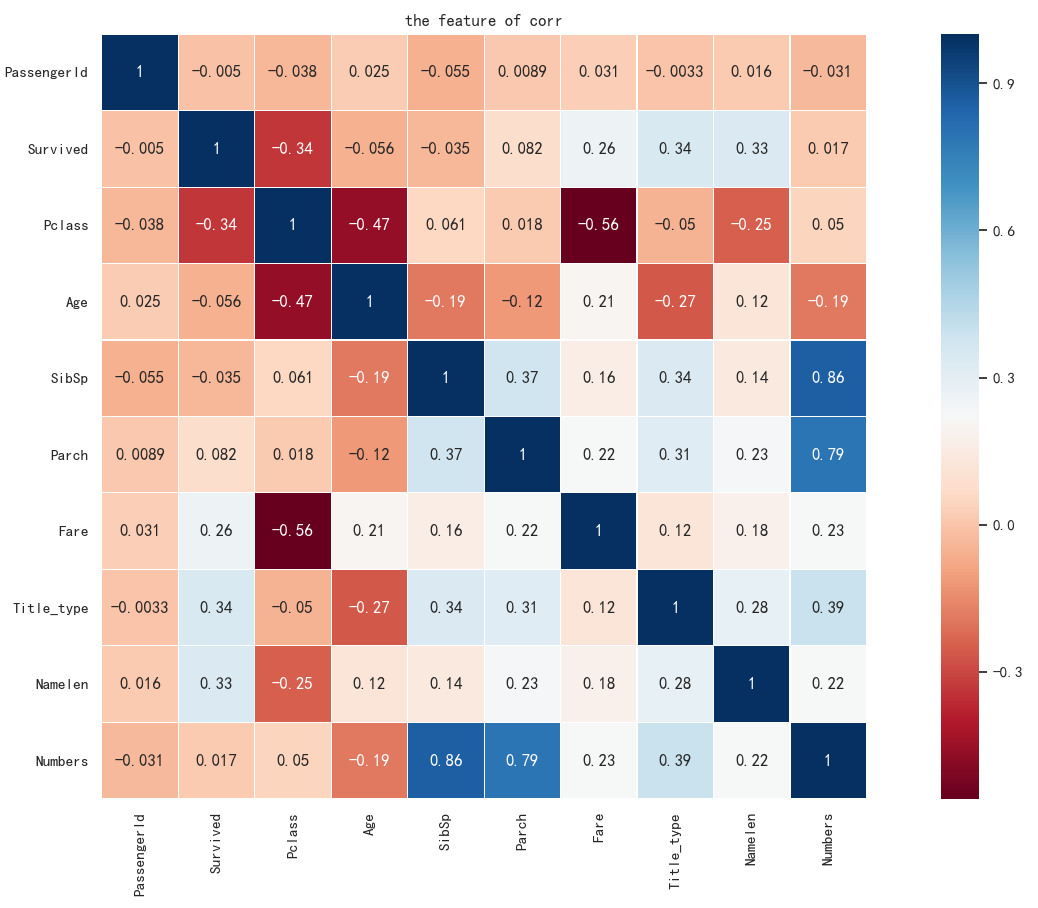
可以很明显的看出特征之间的关联性
如何选择和生还率最相关的特征?直接看会不会有点不严谨?
是的,上面的图只是让你大概明白特征之间的关联情况,具体哪个特征会对最终的结果影响比较大,还需要借助神秘的力量
这里举个例子,大家参考一下
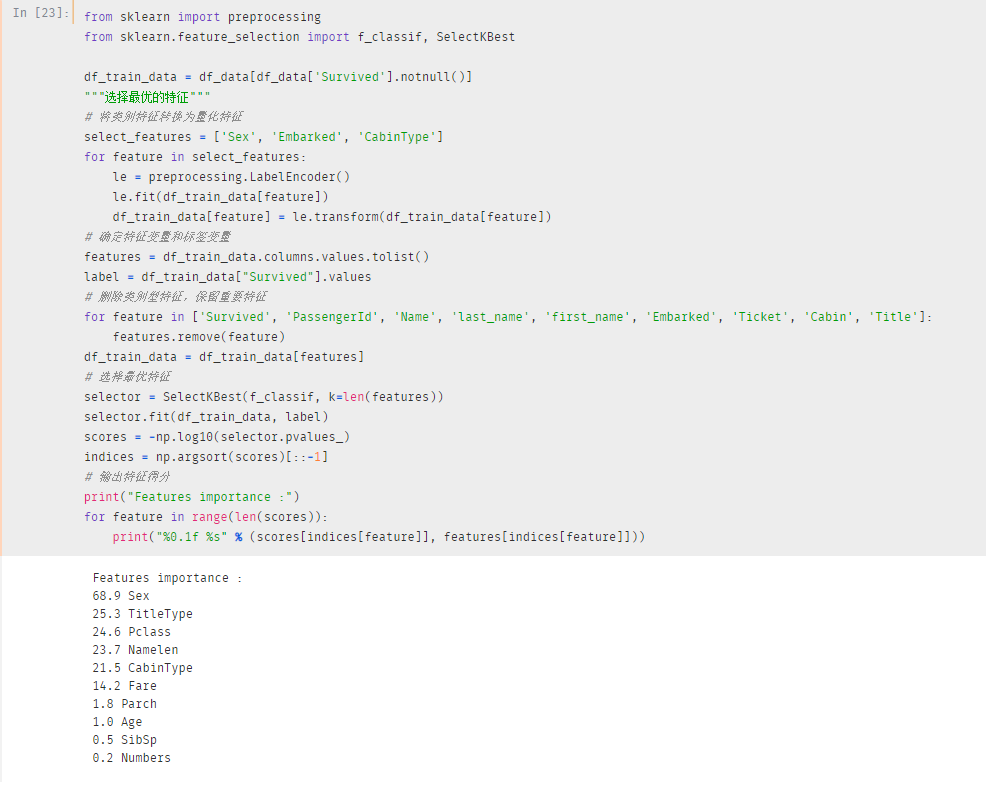
纳尼?可视化部分明明Age 和Numbers 对结果影响很大,这里怎么得分这么低?
这里需要用到特征工程的思想,简单说一下
我们知道Age 的大小对于结果是有影响的,但是在数据集中Age 的分布范围太广了
测试数据一共800+条,结果Age 的取值结果就有80+种,对应的Age 的权重也会有所降低
所以,我们需要对Age 进行数据划分,例如:0~15定义为儿童、15 ~ 30定义为青年,30以上定义为中年
同样的道理,家庭成员数Numbers 也可以采用同样的处理方法
这个属于特征工程的知识,数据分析的就到此为止了
其实今天的结论在可视化部分就已经写明白了,稍稍总结一下就有了
然鹅小一知道你们懒得再往回翻,于是就在这又添油加醋的总结了一番:
-
当之无愧的“Lady First”,在灾难面前,女士、小孩拥有优先选择权
-
中上层人士占据一定的领导地位,包括在面对生死
-
底层人士多年龄较小,金钱和地位都缺失
-
独生子女的社会地位优于多孩的社会地位
-
一个人旅行比较容易出事(文中的出事指的是遇难),尽量和父母、兄弟姐妹一起
-
西方国家对于儿童和成人的年龄划分点是15岁,不同于中国的18岁成年
很感谢上篇文章大家的认可,小一确实是花了心思的,也确实是没有填完所有的坑,这个真的抱歉
有的时候真的就只是感兴趣,觉得好玩然后就去搞了,钻进去了之后才发现原来并不简单
在很多时候,我们需要的就是这样一种兴趣,培养起来了,它就会成为你的一个敲门砖
在技术之路上,也有很多的困难与挫折,但是那又能怎样,只要我们一直在路上,就一定不会孤单前行。