readme:
运行顺序
我们拟分三批抓取论文信息
- 首先抓取详细信息,包括文章的
题目,第一作者,单位,期刊,关键词 - 其次抓取简要信息,包括文章的
题目,全部作者,期刊名称,发表时间,被引次数,下载次数 - 最后抓取文章的
题目和摘要
这里要说明的是,我分三次抓取的最主要原因是,知网详细界面和简略界面所显示的内容有所差异,为了全方位获取文章的信息,我们分批次抓取,最后可根据文章题目按需横向合并(merge)
我们首先手动操作,感受下检索过程,便于明确爬虫各个步骤的操作。
首先第一步是打开知网高级检索网页,这一步应该没有任何困难
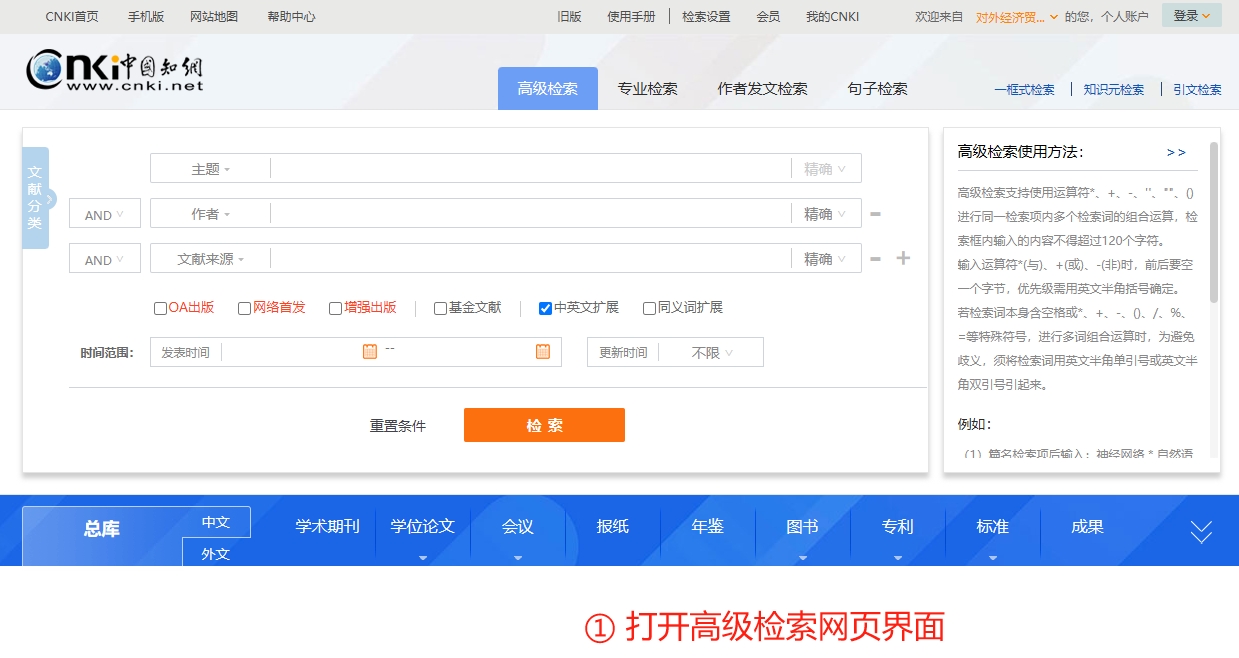
然后,我们点击主题栏,再键入“数字贸易”,完成后点击“检索”
如下图所示
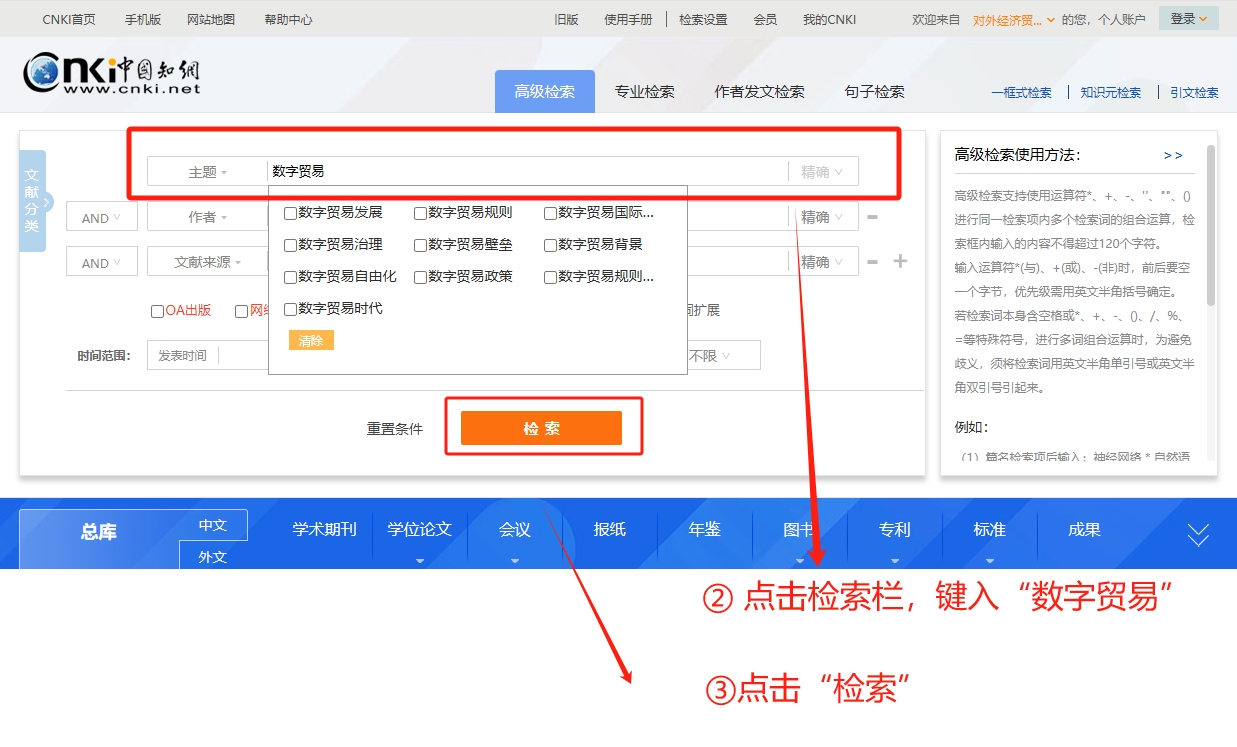
在点击完检索后,会跳出如下界面。此时,我们要爬取的是学术期刊,因此先点击④所示的“学术期刊”。在点击完成后,期刊类型(CSSCI、CSCD、AMI)就会自动显示,此时如果我们要筛选南大核心期刊的话,还需要勾选CSSCI前的方框。
最后,为了显示论文的详细信息,我们要点击如⑥所示的详细信息。
为了减少翻页,提高单一页面的阅读容量,我们还可以把“每页20篇”下拉选项框改为“每页50篇”
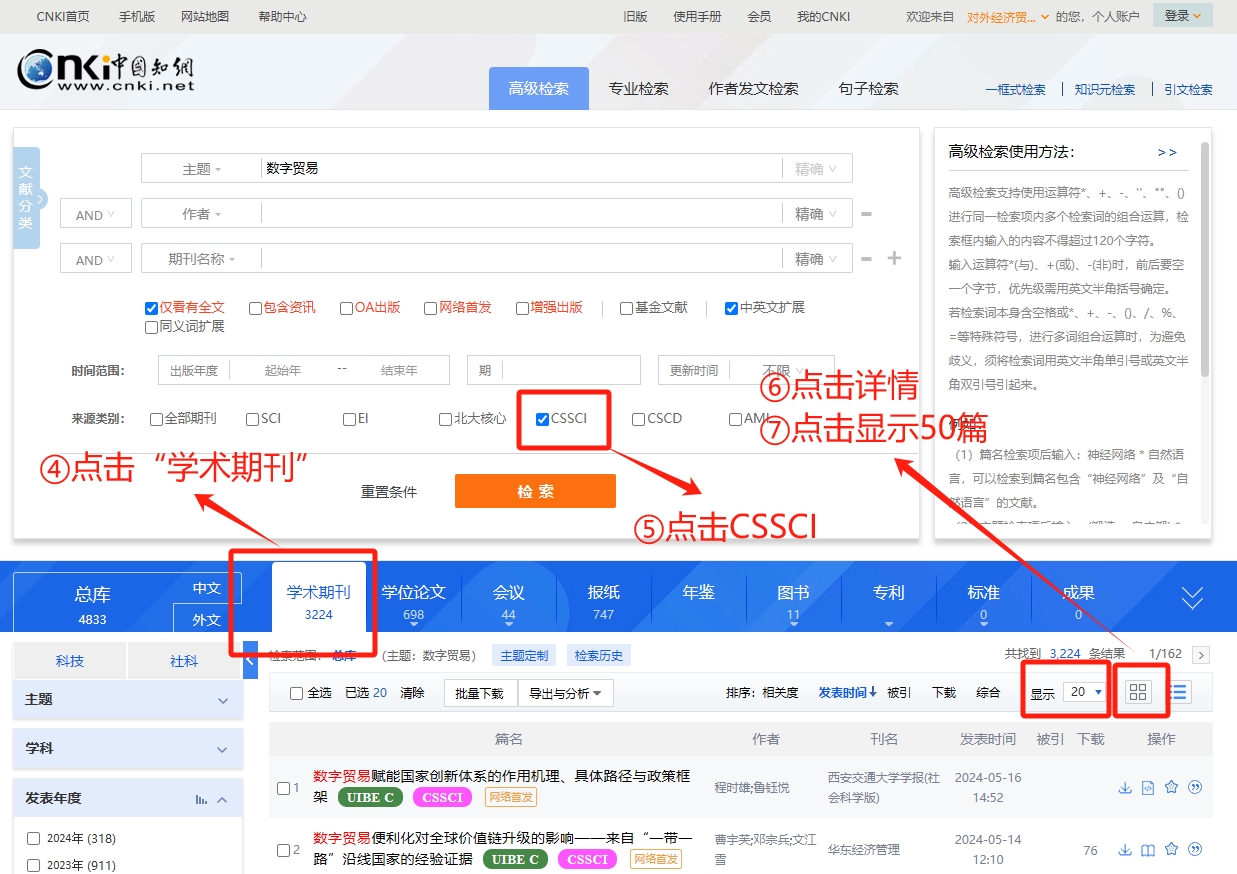
至此,我们就人为模拟了文献的检索过程。
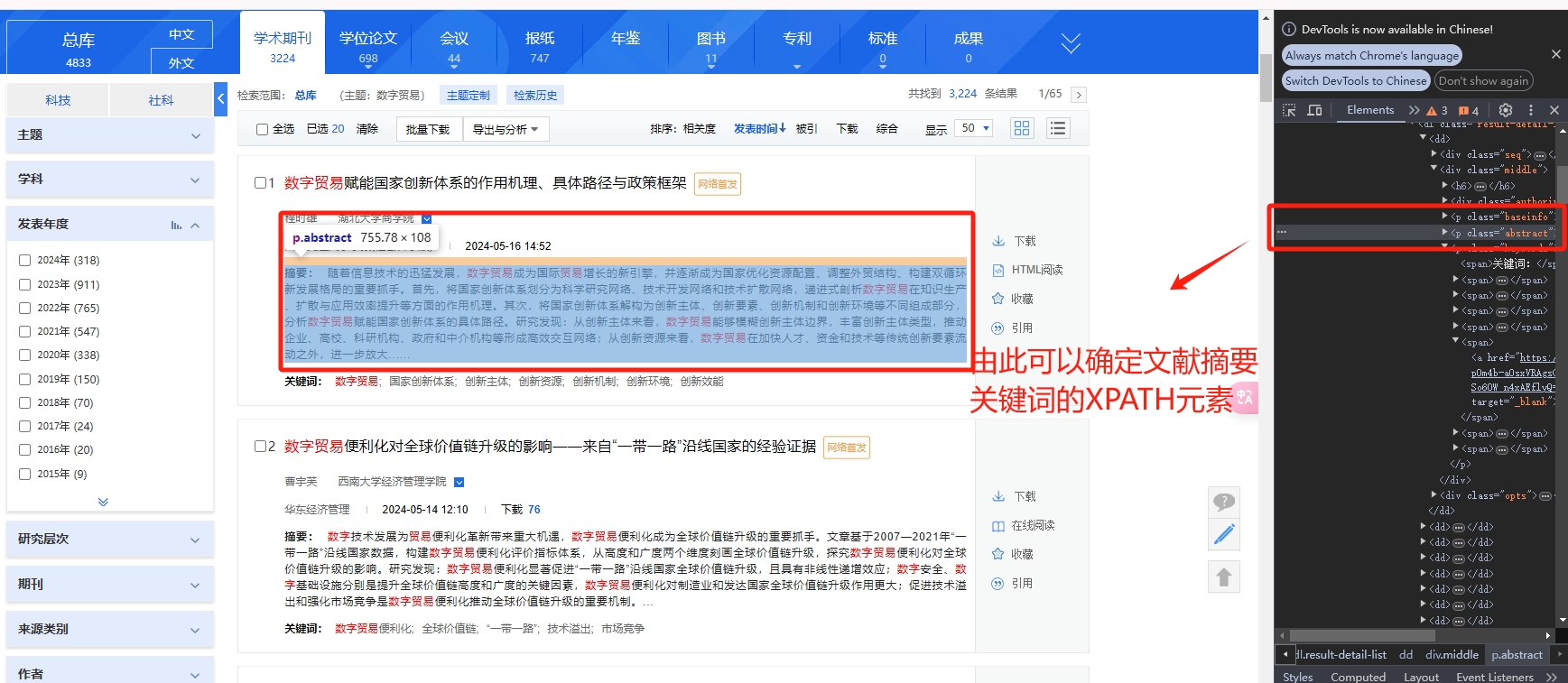
在检索完成后,应当会呈现出如下界面。在该界面中,我们能够看到符合筛选条件的文章名、发表时间、关键词、第一作者、第一作者所在机构等详细信息。我们可以通过检查页面上的元素来确定XPATH路径,进而完成页面相关元素的抓取。
下面,我们通过python来抓取这些元素。
我们拟分三批抓取论文信息
- 首先抓取详细信息,包括文章的
题目,第一作者,单位,期刊,关键词,在爬取时应当在详细页面(如上图第⑥步所示) - 其次抓取简要信息,包括文章的
题目,全部作者,期刊名称,发表时间,被引次数,下载次数,在爬取时应不用点详细模式(不用点击上图第⑥步) - 最后抓取文章的
题目和摘要
这里要说明的是,我分三次抓取的最主要原因是,知网详细界面和简略界面所显示的内容有所差异,为了全方位获取文章的信息,我们分批次抓取,最后可根据文章题目按需横向合并(merge)
---------------------------------