Performance Benchmarks
Our design philosophy is to provide high quality compact models balancing between capacity and adequate quality.
It is widely known (also confirmed by our own research) that you can get incremental improvements by scaling your model further 2x, 5x, 10x. But we believe firmly that performance gains should be achieved on similar or lower computation budget.
There are novel techniques that might enable packing models close to EE performance into packages as small as 10-20 MB, but for now the lowest we could achieve was about 50 MB for EE models.
| Model | Params, M | Model size CE, MB | Model size EE, MB |
|---|---|---|---|
| EN V1 | 45.6 | 182 | ~45.5 (EE) |
| DE V1 | 45.6 | 182 | ~45.5 (EE) |
| ES V1 | 52.8 | 211 | ~52.75 (EE) |
It is customary to publish Multiply-Adds or FLOPS as a measure of compute required, but we prefer just sharing model sizes and tests on commodity hardware.
All of the below benchmarks and estimates were run on 6 cores (12 threads) of AMD Ryzen Threadripper 1920X 12-Core Processor (3500 МHz). Scale accordingly for your device. These tests are just run as is using native PyTorch, without any clever batching / concurrency techniques. You are welcome to submit your test results!
Test procedure:
- We take 100 10-second audio files
- Split into batches of 1, 5, 10, 25 files
- Measure how long it takes to process a batch of a given size on CPU
- On GPU our models are so fast that batch size and audio length do no really matter (in practical cases)
- We measure how many seconds of audio per second one processor core can process. This is similer to
1 / RTFper core
We report results for the following types of models:
- FP32 (baseline)
- FP32 + Fused (CE)
- FP32 + INT8
- FP32 Fused + INT8
- Full INT8 + Fused (EE)
Seconds of audio per second per core (1 / RTF per core):
| Batch size | FP32 | FP32 + Fused | FP32 + INT8 | FP32 Fused + INT8 | Full INT8 + Fused |
|---|---|---|---|---|---|
| 1 | 7.7 | 8.8 | 8.8 | 9.1 | 11.0 |
| 5 | 11.8 | 13.6 | 13.6 | 15.6 | 17.5 |
| 10 | 12.8 | 14.6 | 14.6 | 16.7 | 18.0 |
| 25 | 12.9 | 14.9 | 14.9 | 17.9 | 18.7 |
Improvements compared to baseline:
| Batch size | FP32 + Fused | FP32 + INT8 | FP32 Fused + INT8 | Full INT8 + Fused |
|---|---|---|---|---|
| 1 | 14% | 14% | 18% | 42% |
| 5 | 16% | 16% | 32% | 48% |
| 10 | 15% | 15% | 31% | 41% |
| 25 | 15% | 15% | 39% | 44% |
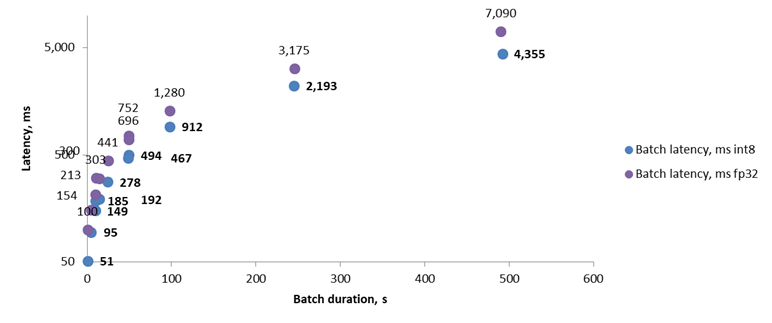
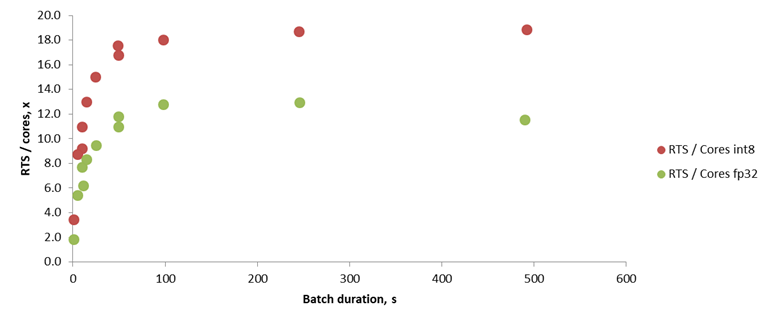
We are not yet decided on which speed improvements should trickle down from EE to CE for which languages.
