You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Hello, Please answer this I have been stuck for a while.
When I am trying to inference from my trained model the inference is being done and audio is saved as it should be, but when I am trying to do voice conversion with following command: tts --model_path output_multilingual//checkpoint_20000.pth --config_path output_multilingual/config.json --reference_wav target_content/asura_10secs.wav --language_idx hi --speaker_idx yayati
I am receiving the following error.
RuntimeError: Expected tensor for argument #1 'indices' to have one of the following scalar types: Long, Int; but got torch.FloatTensor instead (while checking arguments for embedding)
I tried to check what is going wrong but since I was able to inference for text to speech with the same model and config I am unable to figure out what might be causing the issue.
I have used speaker_embedding and not the d_vectors
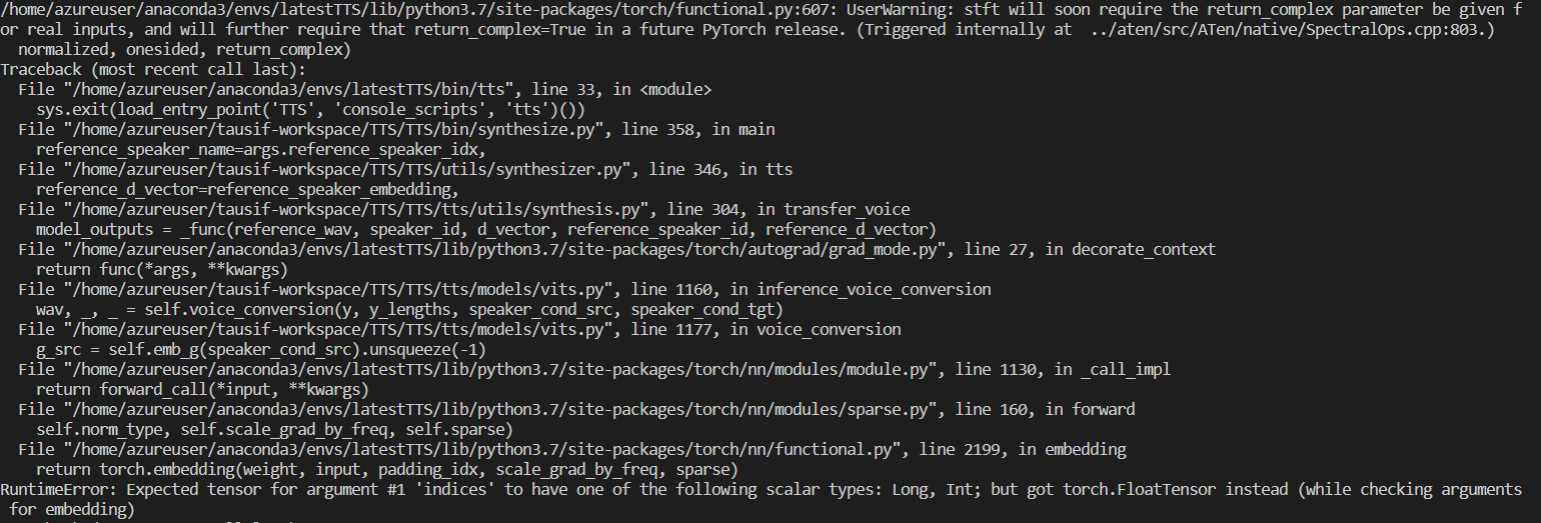
Below I have attached full error log.
reacted with thumbs up emoji reacted with thumbs down emoji reacted with laugh emoji reacted with hooray emoji reacted with confused emoji reacted with heart emoji reacted with rocket emoji reacted with eyes emoji
Uh oh!
There was an error while loading. Please reload this page.
-
Hello, Please answer this I have been stuck for a while.
When I am trying to inference from my trained model the inference is being done and audio is saved as it should be, but when I am trying to do voice conversion with following command:
tts --model_path output_multilingual//checkpoint_20000.pth --config_path output_multilingual/config.json --reference_wav target_content/asura_10secs.wav --language_idx hi --speaker_idx yayatiI am receiving the following error.
RuntimeError: Expected tensor for argument #1 'indices' to have one of the following scalar types: Long, Int; but got torch.FloatTensor instead (while checking arguments for embedding)
I tried to check what is going wrong but since I was able to inference for text to speech with the same model and config I am unable to figure out what might be causing the issue.
I have used speaker_embedding and not the d_vectors
Below I have attached full error log.
Beta Was this translation helpful? Give feedback.
All reactions