Replies: 4 comments 11 replies
-
|
Here is a model to vocoder compatibility matrix based on my testing (English, ljspeech released models):
|

Beta Was this translation helpful? Give feedback.
-
|
@erogol what are some of the reasons for the model and vocoder compatibility issues? It's a practical question when training for a new language - which model/vocoder pair to choose for training? Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
because they are not meant to be together. They use different audio processing params |
Beta Was this translation helpful? Give feedback.
-
|
@erogol, are there any more details somewhere about the audio processing params? I am training a glow-tts and mb-melgan for the Russian language. What should I be using for the audio parameters? Thank you |
Beta Was this translation helpful? Give feedback.
-
|
@erogol just to clarify, I am not sure I am using the right parameters for the training of the glow_tts and mb_melgan combo. I am capturing the results here for the training of the Russian model. Basically, the training audio results of the model and a vocoder on the RUSLAN dataset are sounding great separately (tensorboard). Together, there is a distinct metallic sound. Glow_TTS:
MB_Melgan:
|
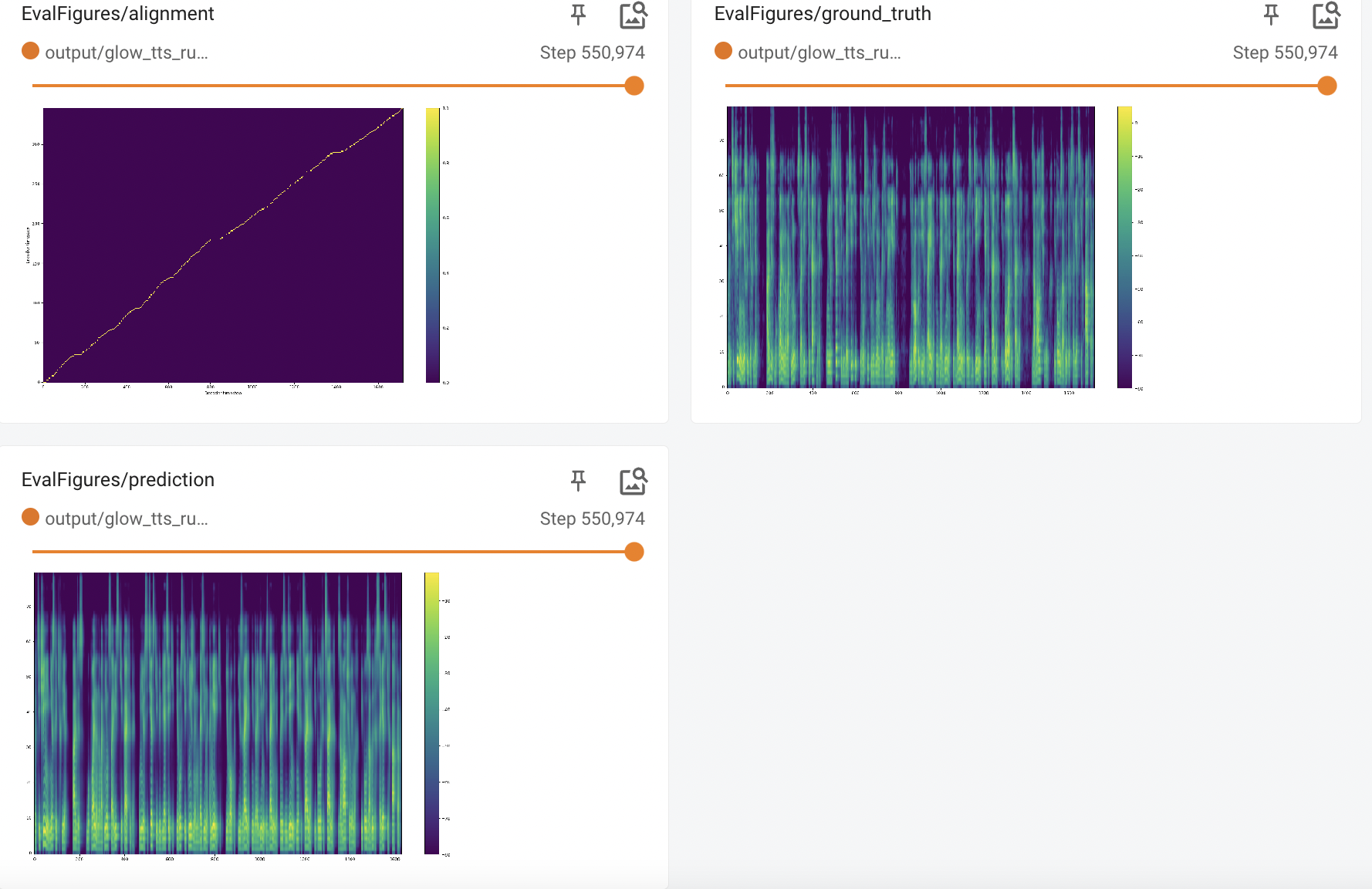
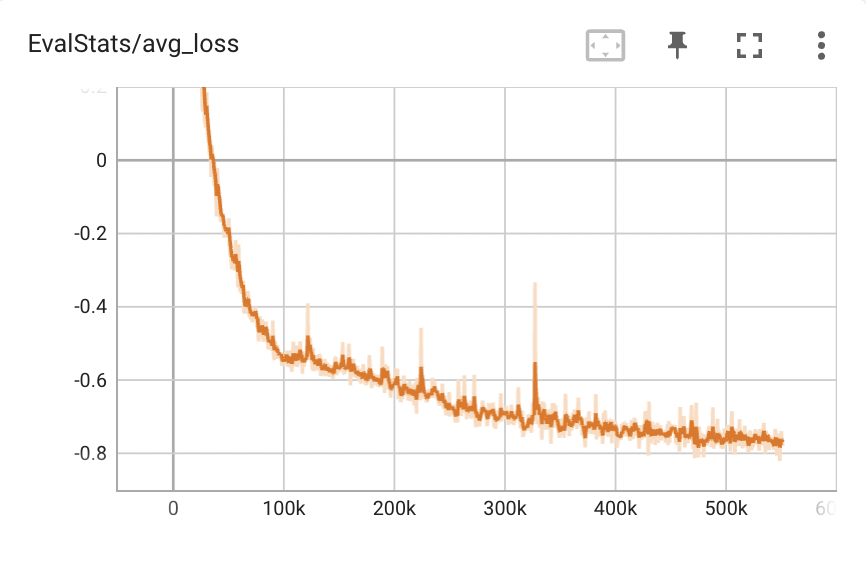
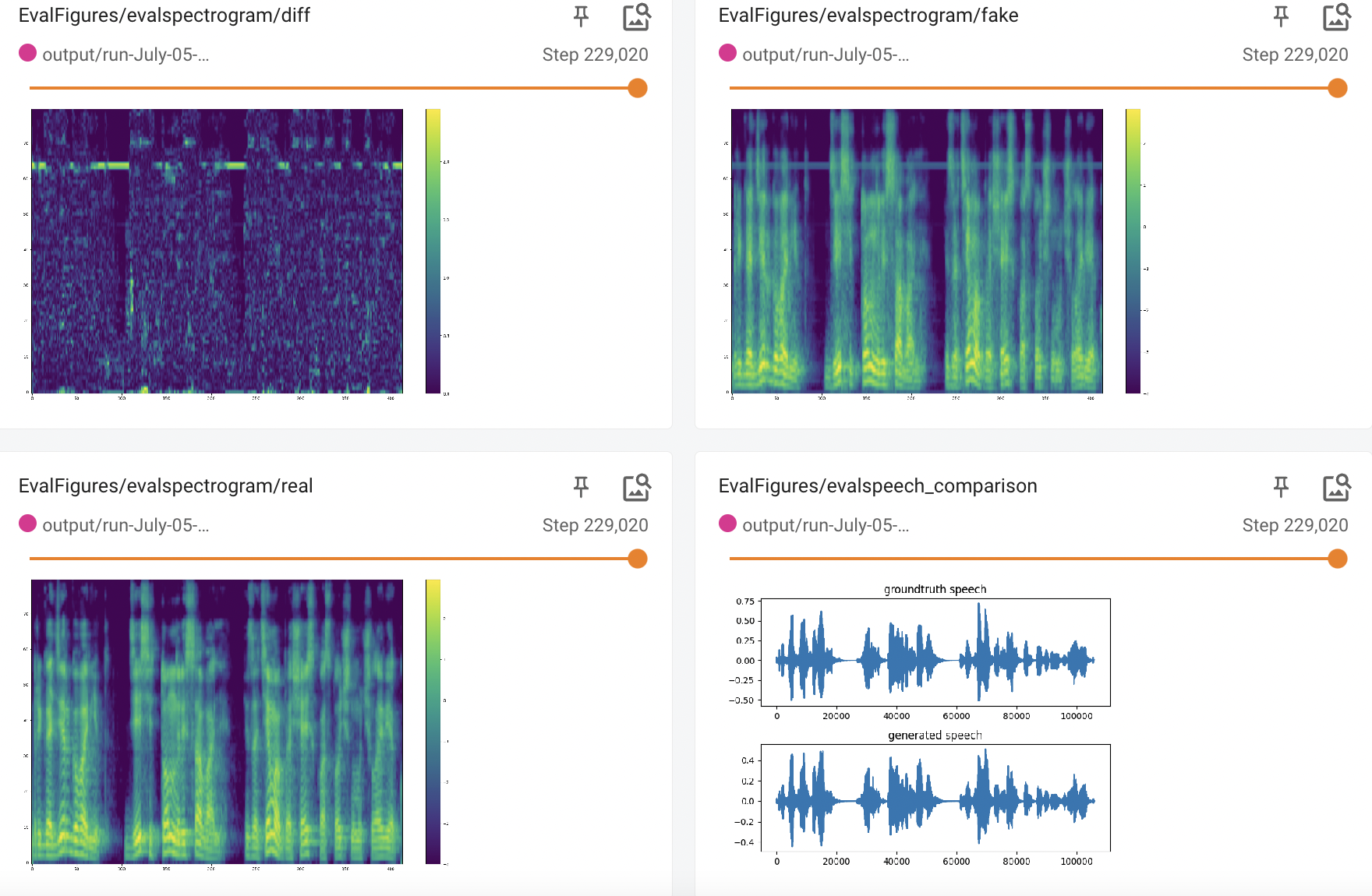
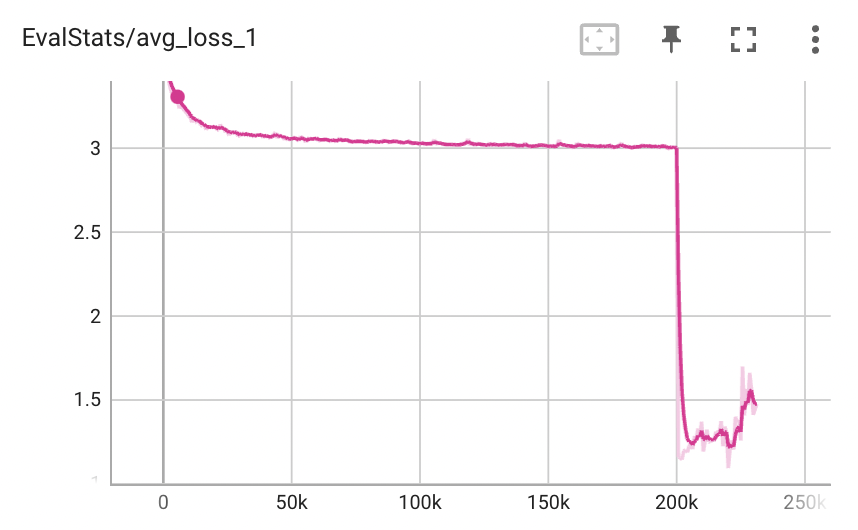
Beta Was this translation helpful? Give feedback.
-
|
@erogol an update, somewhere after 500K steps, the glow_tts+mb_melgan started sounding decent together. I posted the best model audio in the discussion. |
Beta Was this translation helpful? Give feedback.
-
|
any blind compatible summeries please? I'm one of the blind people who's interested in coqui tts, so hope the developers and contributors agree on a rule to summerize any graphical or image stuff, except the tts spectrograms. The summerized images include those benchmarks like this one, errors etc |
Beta Was this translation helpful? Give feedback.
-
|
The detail page in the spreadsheet is here. Summary page is here. |
Beta Was this translation helpful? Give feedback.
-
|
I don't know how to work with spreadsheets on the web but that falls on me. Other blind people encounter spreadsheets and use them enough but I've never needed to so far, in any case thanks for the effort, who knows if someone else can bennifit from this |
Beta Was this translation helpful? Give feedback.
-
|
@king-dahmanus how does this one work: Detail Table:
Summary Table:
|
Beta Was this translation helpful? Give feedback.
-
|
Every model comes with a default vocoder set for it. You don't need to try a different vocoder. Doesn't make sense. |
Beta Was this translation helpful? Give feedback.
-
Hi, Trying to learn more about Coqui TTS. How to I find out what is the default vocoder for each model ? Is there some documentation I can refer to ? |
Beta Was this translation helpful? Give feedback.
-
|
I think this .models.json file is a good place to start. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @iprovalo for the heads-up. |
Beta Was this translation helpful? Give feedback.
-
|
@iprovalo perfect. Thanks! |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I want to share some tests I ran Raspberry Pi - RPi (8g memory, only used single CPU in this test) as well as on a cloud instance. The set up is:
"PyTorch_version": "1.11.0a0+gitbc2c6ed", "TTS": "0.7.1", "numpy": "1.21.6", "python": "3.9.2","PyTorch_version": "1.11.0+cu115", "TTS": "0.7.0", "numpy": "1.21.6", "python": "3.7.13",I was measuring the processing speed and quality on both. I also wanted to specifically compare the quality relative to the compatibility of the models to vocoders. I tested seven models and three vocoders. Quality had three gradations -
Clear,Metallic, noisy,Unintelligible, all measured by myself. I used the git clone installation in both cases for Coqui-AI TTS and pre-trained models/vocoders:I had to disable torchaudio in order to run on Raspberry Pi as mentioned here.
I used ljspeech English dataset based configurations - six models, and three vocoders, plus vits (combined model and vocoder).
Here are some observations:
glow-tts+mb_melgan(Clear quality, RPi:1.73 sec).base_encoder.pyto get it to work without the torchaudio. Vits relies on torchaudio to load the audio item (and resampling if required)glow-tts+hifigan_v2,speedy-speech+hifigan_v2,speedy-speech+multiband-melganFull spreadsheet with results, including the commands I ran. The spreadsheet is open for the comments.
Output wav files.
I hope this is helpful.
Beta Was this translation helpful? Give feedback.
All reactions